Snowflake ADA-C01 Exam Questions
Questions for the ADA-C01 were updated on : Feb 18 ,2026
Page 1 out of 6. Viewing questions 1-15 out of 78
Question 1
An Administrator needs to implement an access control mechanism across an organization. The
organization users access sensitive customer data that comes from different regions and needs to be
accessible for Analysts who work in these regions. Some Analysts need very specific access control
depending on their functional roles in the organization. Following Snowflake recommended practice,
how should these requirements be met? (Select TWO).
- A. Implement views on top of base tables that exclude or mask sensitive data.
- B. Implement row access policies and Dynamic Data Masking policies.
- C. Include masking rules as part of data ingestion and transformation pipelines.
- D. Use a third-party tool to share the data.
- E. Use zero-copy cloning to replicate the database schema and provide access as needed.
Answer:
AB
Explanation:
The scenario describes a need for fine-grained access control over sensitive customer data across
multiple regions, with functional-role-based access for analysts. Snowflake recommends applying a
layered security model that separates raw data from user-facing access and leverages built-in policy
features.
Explanation of Correct Answers:
A . Implement views on top of base tables that exclude or mask sensitive data.
Creating secure views allows administrators to abstract sensitive fields or filter out certain rows and
columns.
It enables role-based access control by granting specific roles access only to the secure views.
Common practice is to restrict access to base tables and give users access to views that enforce
business logic and data access rules.
B . Implement row access policies and Dynamic Data Masking policies.
Row Access Policies control access at the row level, determining what data a user can see based on
their role or session context.
Dynamic Data Masking allows you to mask sensitive column data (like PII) dynamically based on the
accessing role.
Both are central features of Snowflake’s fine-grained access control.
Why the other options are incorrect:
C . Include masking rules as part of data ingestion and transformation pipelines.
This is not a Snowflake-recommended best practice for access control.
It hardcodes data access rules into ETL/ELT logic, which reduces flexibility and central control.
Also, it masks the data permanently at ingestion time, rather than dynamically at query time.
D . Use a third-party tool to share the data.
Snowflake supports native Secure Data Sharing, and using a third-party tool is unnecessary and
introduces complexity.
It does not address row/column-level access control within Snowflake itself.
E . Use zero-copy cloning to replicate the database schema and provide access as needed.
Zero-copy cloning is ideal for testing, development, and backup purposes, not for controlling access.
It duplicates metadata but doesn’t provide a mechanism for fine-grained, real-time access control.
SnowPro Administrator Reference:
Row Access Policies Overview
Dynamic Data Masking Overview
Access Control Best Practices
Using Secure Views for Access Control
Question 2
A resource monitor named MONTHLY_FINANCE_LIMIT has been created and applied to two virtual
warehouses (fin_wh1 and fin_wh2) using the following SQL: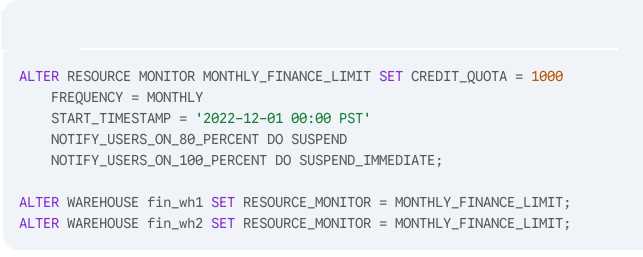
Given that the combined total of credits consumed by fin_wh1 and fin_wh2 (including cloud services)
has reached 800 credits and both warehouses are suspended, what should the ACCOUNTADMIN
execute to allow both warehouses to be resumed? (Select TWO).
- A. ALTER WAREHOUSE fin_wh1 RESUME;
- B. ALTER WAREHOUSE fin_wh2 RESUME;
- C. ALTER WAREHOUSE fin_wh1 UNSET RESOURCE_MONITOR MONTHLY_FINANCE_LIMIT;
- D. ALTER WAREHOUSE fin_wh2 UNSET RESOURCE_MONITOR MONTHLY_FINANCE_LIMIT;
- E. ALTER RESOURCE MONITOR MONTHLY_FINANCE_LIMIT SET CREDIT_QUOTA = 1500;
- F. ALTER RESOURCE MONITOR MONTHLY_FINANCE_LIMIT RESET;
- G. ALTER WAREHOUSE fin_wh1 UNSET RESOURCE_MONITORS;
Answer:
EF
Explanation:
❗
Scenario:
Resource Monitor MONTHLY_FINANCE_LIMIT has a credit quota of 1000.
800 credits have been used and warehouses are already suspended.
According to monitor configuration:
At 80%, warehouses are suspended.
At 100%, warehouses would be suspended immediately.
Warehouses cannot resume until the monitor is reset or the quota is increased.
✅
E. SET CREDIT_QUOTA = 1500
Increases the monthly credit limit to 1500.
Since current usage is 800 < 1500, this puts usage below 80%.
This allows resumption of warehouses.
✅
F. RESET
sql
CopyEdit
ALTER RESOURCE MONITOR MONTHLY_FINANCE_LIMIT RESET;
Resets usage to zero for the current period.
Allows warehouses to resume immediately — same effect as a fresh cycle.
❌
Why Other Options Are Incorrect:
A . / B. ALTER WAREHOUSE ... RESUME
Won’t work while the resource monitor is actively suspending the warehouses due to limits.
C . / D. UNSET RESOURCE_MONITOR
You can’t remove a resource monitor from a warehouse while it is currently suspended by that same
monitor.
You must first reset or adjust the monitor.
G . UNSET RESOURCE_MONITORS
Invalid syntax — there’s no RESOURCE_MONITORS plural keyword.
SnowPro Administrator Reference:
Resource Monitors Overview
ALTER RESOURCE MONITOR
Best Practices for Controlling Warehouse Credit Usage
Question 3
A user accidentally truncated the data from a frequently-modified table. The Administrator has
reviewed the query history and found the truncate statement which was run on 2021-12-12 15:00
with query ID 8e5d0ca9-005e-44e6-b858-a8f5b37c5726. Which of the following statements would
allow the Administrator to create a copy of the table as it was exactly before the truncated statement
was executed, so it can be checked for integrity before being inserted into the main table?
- A. CREATE TABLE RESTORE_TABLE CLONE CURRENT_TABLE BEFORE (timestamp => '2021-12-12 00:00');
- B. SELECT * FROM CURRENT_TABLE before (statement => '8e5d0ca9-005e-44e6-b858- a8f5b37c5726');
- C. INSERT INTO CURRENT_TABLE SELECT * FROM CURRENT_TABLE before (statement => '8e5d0ca9- 005e-44e6-b858-a8f5b37c5726');
- D. CREATE TABLE RESTORE_TABLE CLONE CURRENT_TABLE before (statement => '8e5d0ca9-005e- 44e6-b858-a8f5b37c5726');
Answer:
D
Explanation:
❗
Scenario:
A TRUNCATE command was accidentally run on a frequently modified table.
Query ID and timestamp are known.
Goal: restore a copy of the table as it existed right before the problematic statement, without
affecting the current table.
✅
Why Option D is Correct:
sql
CopyEdit
CREATE TABLE RESTORE_TABLE CLONE CURRENT_TABLE
BEFORE (STATEMENT => '8e5d0ca9-005e-44e6-b858-a8f5b37c5726');
This uses Zero-Copy Cloning + Time Travel.
The BEFORE (STATEMENT => ...) clause restores the exact state of the table before the TRUNCATE ran.
Creating a clone ensures the original table remains untouched for integrity checks before merging
data back.
❌
Why Others Are Incorrect:
A . BEFORE (timestamp => '2021-12-12 00:00')
Wrong timestamp: that’s 15 hours before the truncate happened. Too early; may lose needed
updates.
B . SELECT * FROM CURRENT_TABLE before (statement => …)
Syntax is invalid: SELECT can’t use BEFORE (STATEMENT => ...) directly like this.
C . INSERT INTO CURRENT_TABLE SELECT * FROM CURRENT_TABLE before (statement => …)
Same syntax issue. Also risky — directly inserting into the original table without validating the data
first.
SnowPro Administrator Reference:
Cloning with Time Travel
Time Travel with Statement ID
Question 4
What Snowflake capabilities are commonly used in rollback scenarios? (Select TWO).
- A. SELECT SYSTEM$CANCEL_QUERY('problematic_query_id');
- B. CREATE TABLE prd_table_bkp CLONE prd_table BEFORE (STATEMENT => 'problematic_query_id');
- C. CREATE TABLE prd_table_bkp AS SELECT * FROM TABLE(RESULT_SCAN('problematic_query_id'));
- D. ALTER TABLE prd_table SWAP WITH prd_table_bkp;
- E. Contact Snowflake Support to retrieve Fail-safe data.
Answer:
B, D
Explanation:
Scenario: You want to rollback changes due to a problematic query (e.g., accidental data modification
or corruption). Snowflake provides two powerful tools:
✅
B. CLONE ... BEFORE (STATEMENT => 'query_id')
This uses Time Travel + Zero-Copy Cloning.
You can clone a table as it existed before a specific query.
It creates a full copy of the table's state at that moment without duplicating storage.
Example:
CREATE TABLE prd_table_bkp CLONE prd_table
BEFORE (STATEMENT => '01a2b3c4-0000-0000-0000-123456789abc');
✅
D. ALTER TABLE ... SWAP WITH ...
Once you've cloned the backup, you can swap it with the live table.
This is a fast, atomic operation — ideal for rollback.
Example:
ALTER TABLE prd_table SWAP WITH prd_table_bkp;
❌
Why the Other Options Are Incorrect:
A . SELECT SYSTEM$CANCEL_QUERY(...)
Cancels a currently running query — doesn’t help if the query already executed and caused damage.
C . CREATE TABLE ... AS SELECT * FROM RESULT_SCAN(...)
Reconstructs results, not the original table.
Only captures output rows, not full table state.
Not ideal for rollback.
E . Contact Snowflake Support to retrieve Fail-safe data
Fail-safe is for disaster recovery only, and only accessible by Snowflake support.
It’s not intended for routine rollback or recovery and has a 7-day fixed retention (non-configurable).
SnowPro Administrator Reference:
Zero-Copy Cloning with Time Travel
ALTER TABLE SWAP
System Functions – SYSTEM$CANCEL_QUERY
Fail-safe Overview
Question 5
A Snowflake Administrator needs to retrieve the list of the schemas deleted within the last two days
from the DB1 database.
Which of the following will achieve this?
- A. SHOW SCHEMAS IN DATABASE DB1;
- B. SELECT * FROM SNOWFLAKE.ACCOUNT_USAGE.SCHEMATA;
- C. SELECT * FROM DB1.INFORMATION_SCHEMA.SCHEMATA;
- D. SELECT * FROM SNOWFLAKE.ACCOUNT_USAGE.DATABASES;
Answer:
B
Explanation:
To retrieve a list of schemas deleted within the last 2 days from the DB1 database, you need a
metadata view that includes historical data, including dropped (deleted) objects.
Let’s review the options:
✅
B. SNOWFLAKE.ACCOUNT_USAGE.SCHEMATA
This is the correct choice because:
It includes metadata for all schemas, even deleted ones, within the retention period.
It contains a DELETED column and a DELETED_ON timestamp column.
You can filter rows with:
sql
CopyEdit
SELECT *
FROM SNOWFLAKE.ACCOUNT_USAGE.SCHEMATA
WHERE DELETED IS TRUE
AND DELETED_ON >= DATEADD(DAY, -2, CURRENT_TIMESTAMP())
AND CATALOG_NAME = 'DB1';
❌
A. SHOW SCHEMAS IN DATABASE DB1;
Only shows current (active) schemas — does not include deleted schemas.
❌
C. DB1.INFORMATION_SCHEMA.SCHEMATA
Like option A, this view only includes active schemas in the current database.
No info on deleted schemas is retained.
❌
D. SNOWFLAKE.ACCOUNT_USAGE.DATABASES
This metadata view tracks databases, not individual schemas.
SnowPro Administrator Reference:
SNOWFLAKE.ACCOUNT_USAGE.SCHEMATA documentation
Metadata includes both active and deleted schemas (within retention window).
Question 6
What information is required from the Identity Provider (IdP) to enable federated authentication in
Snowflake? (Select TWO).
- A. IdP account details
- B. URL endpoint for SAML requests
- C. SAML response format
- D. Authentication certificate
- E. IdP encryption key
Answer:
B, D
Explanation:
To enable federated authentication (aka SSO via SAML 2.0) in Snowflake, the integration with an
Identity Provider (IdP) must be configured. This setup involves configuring external authentication
via SAML, and Snowflake needs specific information from the IdP.
Required Information from IdP:
URL Endpoint for SAML Requests (B)
This is often referred to as the SSO URL or SAML 2.0 Endpoint (HTTP).
It's the URL that Snowflake redirects users to for authentication.
In Snowflake's SAML configuration, this is required as the SAML2_ISSUER or SAML2_SSO_URL.
Authentication Certificate (D)
This is the X.509 certificate issued by the IdP.
It's used by Snowflake to validate the digital signature of the SAML assertions sent by the IdP.
It ensures that the SAML response is authentic and not tampered with.
❌
Why Other Options Are Incorrect:
A . IdP account details
Not needed. Snowflake doesn’t require credentials or internal details from the IdP. It relies on
assertions sent via SAML, not stored accounts.
C . SAML response format
Snowflake adheres to SAML 2.0 standard, and expects a compliant format. There's no need to specify
format explicitly — it’s part of the standard protocol.
E . IdP encryption key
Not required by Snowflake. Snowflake verifies SAML assertions via signature validation, not
encryption using the IdP’s private key.
SnowPro Administrator Reference:
Snowflake Documentation — Federated Authentication Setup
https://docs.snowflake.com/en/user-guide/security-fed-auth-use
https://docs.snowflake.com/en/user-guide/security-fed-auth-config
Required IdP Metadata for Snowflake SAML Configuration:
SAML2_SSO_URL: SAML 2.0 POST binding endpoint
SAML2_X509_CERT: Public cert used to validate IdP signatures
Question 7
The ACCOUNTADMIN of Account 123 works with Snowflake Support to set up a Data Exchange. After
the exchange is populated with listings from other Snowflake accounts,
what roles in Account 123 are allowed to request and get data?
- A. Only the ACCOUNTADMIN role, and no other roles
- B. Any role with USAGE privilege on the Data Exchange
- C. Any role with IMPORT SHARE and CREATE DATABASE privileges
- D. Any role that the listing provider has designated as authorized
Answer:
B
Explanation:
To request and get data from a Data Exchange, the role in Account 123 must have the USAGE
privilege on the Data Exchange object. This privilege allows the role to view the listings and request
access to the data. According to the
Snowflake documentation
, “To view the listings in a data
exchange, a role must have the USAGE privilege on the data exchange object. To request access to a
listing, a role must have the USAGE privilege on the data exchange object and the IMPORT SHARE
privilege on the account.” The other options are either incorrect or not sufficient to request and get
data from a Data Exchange. Option A is incorrect, as the ACCOUNTADMIN role is not the only role
that can request and get data, as long as other roles have the necessary privileges. Option C is
incorrect, as the IMPORT SHARE and CREATE DATABASE privileges are not required to request and
get data, but only to create a database from a share after the access is granted. Option D is incorrect,
as the listing provider does not designate the authorized roles in Account 123, but only approves or
denies the requests from Account 123.
Question 8
A Snowflake Administrator is investigating why a query is not re-using the persisted result cache.
The Administrator found the two relevant queries from the SNOWFLAKE. ACCOUNT_USAGE.
QUERY_HISTORY view:
Why is the second query re-scanning micro-partitions instead of using the first query's persisted
result cache?
- A. The second query includes a CURRENT_TIMESTAMP () function.
- B. The second query includes a CURRENT_DATE () function.
- C. The queries are executed with two different virtual warehouses.
- D. The queries are executed with two different roles.
Answer:
A
Explanation:
The inclusion of the CURRENT_TIMESTAMP() function in the second query prevents it from re-using
the first query’s persisted result cache because this function makes each execution unique due to the
constantly changing timestamp. According to the
Snowflake documentation
, “The query does not
include non-reusable functions, which return different results for successive runs of the same query.
UUID_STRING, RANDOM, and RANDSTR are good examples of non-reusable functions.” The
CURRENT_TIMESTAMP() function is another example of a non-reusable function, as it returns the
current date and time at the start of query execution, which varies for each run. Therefore, the
second query is not identical to the first query, and the result cache is not reused. The other options
are either incorrect or irrelevant to the question. Option B is incorrect, as the CURRENT_DATE()
function is a reusable function, as it returns the same value for all queries executed within the same
day. Option C is irrelevant, as the virtual warehouse used to execute the query does not affect the
result cache reuse. Option D is also irrelevant, as the role used to execute the query does not affect
the result cache reuse, as long as the role has the necessary access privileges for all the tables used in
the query.
Question 9
How should an Administrator configure a Snowflake account to use AWS PrivateLink?
- A. Create CNAME records in the DNS.
- B. Contact Snowflake Support.
- C. Block public access to Snowflake.
- D. Use SnowCD to evaluate the network connection.
Answer:
A
Explanation:
To configure a Snowflake account to use AWS PrivateLink, the Administrator needs to create CNAME
records in the DNS that point to the private endpoints provided by Snowflake. This allows the clients
to connect to Snowflake using the same URL as before, but with private connectivity. According to
the
Snowflake documentation
, “After you have created the VPC endpoints, Snowflake provides you
with a list of private endpoints for your account. You must create CNAME records in your DNS that
point to these private endpoints. The CNAME records must use the same hostnames as the original
Snowflake URLs for your account.” The other options are either incorrect or not sufficient to
configure AWS PrivateLink.
Option B is not necessary, as the Administrator can enable AWS
PrivateLink using the SYSTEM$AUTHORIZE_PRIVATELINK function1
.
Option C is not recommended, as
it may prevent some data traffic from reaching Snowflake, such as large result sets stored on AWS
S32
.
Option D is not related to AWS PrivateLink, but to Snowflake Connectivity Diagnostic (SnowCD),
which is a tool for diagnosing network issues between clients and Snowflake3
.
Question 10
An Administrator needs to create a sample of the table LINEITEM. The sample should not be
repeatable and the sampling function should take the data by blocks of rows.
What select command will generate a sample of 20% of the table?
- A. select * from LINEITEM sample bernoulli (20);
- B. select * from LINEITEM sample system (20);
- C. select * from LINEITEM tablesample block (20 rows);
- D. select * from LINEITEM tablesample system (20) seed (1);
Answer:
B
Explanation:
This command will generate a sample of 20% of the table by using the SYSTEM (or BLOCK) sampling
method, which selects each block of rows with a probability of 20/100. This method is suitable for
taking data by blocks of rows, as the question requires. According to the
Snowflake documentation
,
“SYSTEM (or BLOCK): Includes each block of rows with a probability of p/100. Similar to flipping a
weighted coin for each block of rows. This method does not support fixed-size sampling.” The other
options are either incorrect or do not meet the requirements of the question. Option A uses the
BERNOULLI (or ROW) sampling method, which selects each row with a probability of 20/100, but
does not take data by blocks of rows. Option C uses the BLOCK sampling method, but specifies a fixed
number of rows (20) instead of a percentage (20%). Option D uses the SYSTEM sampling method, but
specifies a seed value (1), which makes the sampling repeatable, contrary to the question.
Question 11
A company's Snowflake account has multiple roles. Each role should have access only to data that
resides in the given role's specific region.
When creating a row access policy, which code snippet below will provide privileges to the role
ALL_ACCESS_ROLE to see all rows regardless of region, while the other
roles can only see rows for their own regions?
- A. create or replace row access policy region policy as (region_value varchar) returns boolean -> 'ALL ACCESS_ROLE' = current_role () and exists ( select 1 from entitlement_table where role = current_role () and region = region_value )
- B. create or replace row access policy region policy as (region_value varchar) returns boolean -> exists ( select 1 from entitlement_table where role = current_role () and region = region_value )
- C. create or replace row access policy region policy as (region_value varchar) returns boolean -> 'ALL_ACCESS_ROLE' = current_role () or exists ( select 1 from entitlement_table where role = current_role () and region = region_value )
- D. create or replace row access policy region policy as (region_value varchar) returns boolean -> 'ALL ACCESS ROLE' = current_role () )
Answer:
C
Explanation:
This code snippet will create a row access policy that returns true if the current role is
ALL_ACCESS_ROLE or if the current role matches the region value in the entitlement_table. This
means that the ALL_ACCESS_ROLE can see all rows regardless of region, while the other roles can
only see rows for their own regions. According to the
Snowflake documentation
, the CURRENT_ROLE
context function returns the name of the current role for the session. The EXISTS function returns
true if the subquery returns any rows. The OR operator returns true if either operand is true.
Therefore, this code snippet satisfies the requirements of the question.
Question 12
Review the output of the SHOW statement below which displays the current grants on the table DB1.
S1. T1: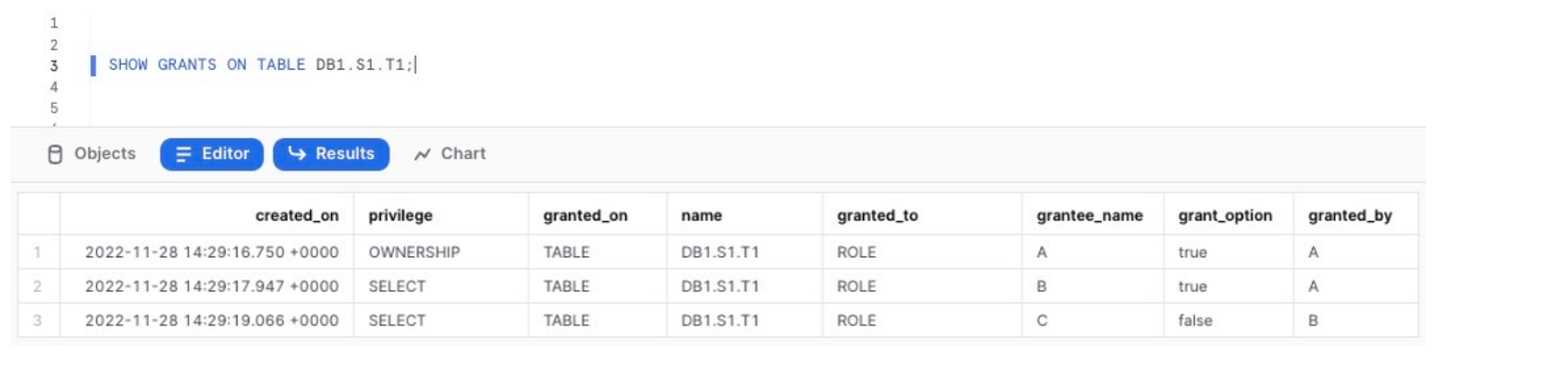
This statement is executed:
USE ROLE ACCOUNTADMIN;
DROP ROLE A;
What will occur?
- A. The table object DB1. S1. T1 will be dropped.
- B. The OWNERSHIP privilege on table DB1. S1. T1 will be transferred to the ACCOUNTADMIN role.
- C. The SELECT privilege on table DB1. S1. T1 to role B will be shown as GRANTED_BY the role ACCOUNTADMIN.
- D. The SELECT privileges for roles B and C will remain.
Answer:
D
Explanation:
Dropping role A does not affect the SELECT privileges granted to roles B and C on the table DB1.S1.T1.
According to the
Snowflake documentation
, dropping a role revokes all privileges granted to the role,
but does not revoke any privileges granted by the role. Therefore, the OWNERSHIP privilege on the
table DB1.S1.T1 will be revoked from role A, but the SELECT privileges granted by role A to role B and
by role B to role C will remain. The GRANTED_BY column will still show the original grantor of the
privilege, not the ACCOUNTADMIN role.
Question 13
Which statement allows this user to access this Snowflake account from a specific IP address
(192.168.1.100) while blocking their access from anywhere else?
- A. CREATE NETWORK POLICY ADMIN_POLICY ALLOWED_IP_LIST = ('192.168.1.100'); ALTER USER ABC SET NETWORK_POLICY = 'ADMIN_POLICY'; User ABC is the only user with an ACCOUNTADMIN role.
- B. CREATE NETWORK POLICY ADMIN POLICY ALLOWED_IP_LIST = ('192.168.1.100'); ALTER ROLE ACCOUNTADMIN SET NETWORK_POLICY = 'ADMIN_POLICY';
- C. CREATE NETWORK POLICY ADMIN_POLICY ALLOWED IP LIST = ('192.168.1.100') BLOCKED_IP_LIST = ('0.0.0.0/0'); ALTER USER ABC SET NETWORK_POLICY = 'ADMIN_POLICY';
- D. CREATE OR REPLACE NETWORK POLICY ADMIN_POLICY ALLOWED_IP_LIST = ('192.168. 1. 100/0') ; ALTER USER ABC SET NETWORK_POLICY = 'ADMIN_POLICY';
Answer:
C
Explanation:
Option C creates a network policy that allows only the IP address 192.168.1.100 and blocks all other
IP addresses using the CIDR notation 0.0.0.0/01
. It then applies the network policy to the user ABC,
who has the ACCOUNTADMIN role. This ensures that only this user can access the Snowflake account
from the specified IP address, while blocking their access from anywhere else. Option A does not
block any other IP addresses, option B applies the network policy to the role instead of the user, and
option D uses an invalid CIDR notation.
Question 14
In general, the monthly billing for database replication is proportional to which variables? (Select
TWO).
- A. The frequency of changes to the primary database as a result of data loading or DML operations
- B. The amount of table data in the primary database that changes as a result of data loading or DML operations
- C. The frequency of the secondary database refreshes from the primary database
- D. The number of times data moves across regions and/or cloud service providers between the primary and secondary database accounts
- E. The number and size of warehouses defined in the primary account
Answer:
AB
Explanation:
Snowflake charges for database replication based on two categories: data transfer and compute
resources1. Data transfer costs depend on the amount of data that is transferred from the primary
database to the secondary database across regions and/or cloud service providers2. Compute
resource costs depend on the use of Snowflake-provided compute resources to copy data between
accounts across regions1. Both data transfer and compute resource costs are proportional to the
frequency and amount of changes to the primary database as a result of data loading or DML
operations3. Therefore, the answer is A and B. The other options are not directly related to the
replication billing, as the frequency of secondary database refreshes does not affect the amount of
data transferred or copied4, and the number and size of warehouses defined in the primary account
do not affect the replication process5.
Question 15
What roles can be used to create network policies within Snowflake accounts? (Select THREE).
- A. SYSADMIN
- B. SECURITYADMIN
- C. ACCOUNTADMIN
- D. ORGADMIN
- E. Any role with the global permission of CREATE NETWORK POLICY
- F. Any role that owns the database where the network policy is created
Answer:
BCE
Explanation:
Network policies are used to restrict access to the Snowflake service and internal stages based on
user IP address1. To create network policies, a role must have the global permission of CREATE
NETWORK POLICY2. By default, the system-defined roles of SECURITYADMIN and ACCOUNTADMIN
have this permission3. However, any other role can be granted this permission by an administrator4.
Therefore, the answer is B, C, and E. The other options are incorrect because SYSADMIN and
ORGADMIN do not have the CREATE NETWORK POLICY permission by default3, and network policies
are not tied to specific databases5.