oracle 1Z0-449 Exam Questions
Questions for the 1Z0-449 were updated on : Feb 18 ,2026
Page 1 out of 5. Viewing questions 1-15 out of 72
Question 1
You need to create an architecture for your customer’s Oracle NoSQL KVStore. The customer needs to
store clinical and non-clinical data together but only the clinical data is mission critical.
How can both types of data exist in the same KVStore?
A. Store the clinical data on the master node and the non-clinical data on the replica nodes.
B. Store the two types of data in separate partitions on highly available storage.
C. Store the two types of data in two separate KVStore units and create database aliases to mimic
one KVStore.
D. Store the two types of data with differing consistency policies.
Answer:
B
The KVStore is a collection of Storage Nodes which host a set of Replication Nodes. Data is spread
across the Replication Nodes.
Each shard contains one or more partitions. Key-value pairs in the store are organized according to
the key. Keys, in turn, are assigned to a partition. Once a key is placed in a partition, it cannot be
moved to a different partition. Oracle NoSQL Database automatically assigns keys evenly across all
the available partitions.
At a very high level, a Replication Node can be thought of as a single database which contains
key-value pairs.
Replication Nodes are organized into shards. A shard contains a single Replication Node which is
responsible for performing database writes, and which copies those writes to the other Replication
Nodes in the shard.
//docs.oracle.com/cd/E26161_02/html/GettingStartedGuide/introduction.html
Question 2
You are attempting to start KVLite but get an error about the “port being in use”.
What is the reason for the error?
- A. KVLite was trying to register on port 5000 when it was already running.
- B. KVStore was also running, and KVStore and KVLite cannot run simultaneously on the same server.
- C. The listener was not started.
- D. The port was not specified so the default port 3889 (the same port as Enterprise Manager) was used.
Answer:
C
Question 3
Which parameter setting will force Impala to execute queries only on the coordinator node?
A. DISABLE_UNSAFE_SPILLS=TRUE
B. SYNC_DDL=TRUE
C. NUM_NODES=1
D. NUM_SCANNER_THREADS=1
Answer:
C
Limit the number of nodes that process a query, typically during debugging. Only accepts the values
0 (meaning all nodes) or 1 (meaning all work is done on the coordinator node). If you are diagnosing
a problem that you suspect is due to a timing issue due to distributed query processing, you can set
NUM_NODES=1 to verify if the problem still occurs when all the work is done on a single node.
Question 4
Your customer has a requirement to use Oracle Database to access and analyze the data that resides
in Apache Hadoop.
What is the result of executing the following command when using Oracle SQL Connector for
Hadoop?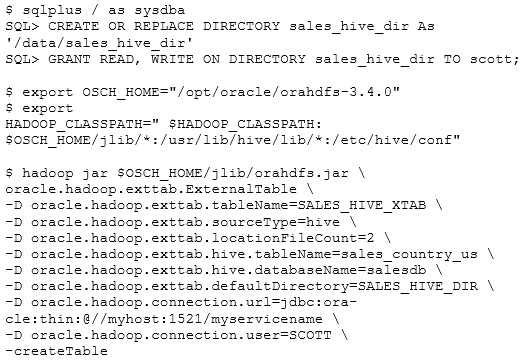
A. An external table called SALES_HIVE_XTAB is created to read data from a Hive table.
B. A Hive table called SALES_HIVE_XTAB is created.
C. Hadoop is configured over JDBC to connect to the Oracle database by using Big Data SQL.
D. An external table called SALES_HIVE_XTAB is created to write data from a Hadoop table.
Answer:
A
You can create external tables automatically using the ExternalTable tool provided in Oracle SQL
Connector for HDFS.
oracle.hadoop.exttab.sourceType=hive
hadoop jar OSCH_HOME/jlib/orahdfs.jar \
oracle.hadoop.exttab.ExternalTable \
[-conf config_file]... \
[-D property=value]... \
-createTable [--noexecute]
| -publish [--noexecute]
| -listlocations [--details]
| -getDDL
//docs.oracle.com/cd/E37231_01/doc.20/e36961/sqlch.htm#BDCUG265
Question 5
Your customer has purchased Big Data SQL and wants to set it up to access its Big Data Appliance
Hadoop and Oracle Exadata Database Server.
How should you enable Oracle Big Data SQL on the Big Data Appliance post installation?
A. mammoth bds=TRUE
B. mammoth big_data_sql=TRUE
C. dbmcli enable big_data_sql
D. emcli enable big_data_sql
E. bdacli enable big_data_sql
Answer:
E
bdacli enable big_data_sql
//docs.oracle.com/cd/E55905_01/doc.40/e55814/admin.htm#BIGUG76694
Question 6
Your customer needs to analyze large numbers of log files after combining them with customer
profile and interaction dat
a. The customer wants to be able to analyze these files back to their go-live date, which was last
October.
Which solution should you choose to accomplish this?
- A. Oracle Database
- B. Hadoop
- C. Berkeley DB
- D. Oracle NoSQL
Answer:
B
Question 7
For Oracle R Advanced Analytics for Hadoop to access the data stored in HDFS, what must the input
files comply with?
A. All the input files for a MapReduce job must be stored in one directory as part of one logical file.
B. Only input files with an underscore (_) are processed.
C. Only files with tab delimiters are supported.
D. Oracle R Advanced Analytics does not have any restrictions on input files.
Answer:
A
All input files for a MapReduce job must be stored in one directory as the parts of one logical file. Any
valid HDFS directory name and file name extensions are acceptable.
//docs.oracle.com/cd/E49465_01/doc.23/e49333/orch.htm#BDCUG397
Question 8
How does the Oracle SQL Connector for HDFS access HDFS data from the Oracle database?
A. NoSQL tables
B. Data Pump files
C. external tables
D. Apache Sqoop files
E. non-partitioned tables
Answer:
B
Using Oracle SQL Connector for HDFS, you can use Oracle Database to access and analyze data
//docs.oracle.com/cd/E37231_01/doc.20/e36961/sqlch.htm#BDCUG126
Question 9
Which user in the following set of ACL entries has read, write and execute permissions?
user::rwx
group::r-x
other::r-x
default:user::rwx
default:user:bruce:rwx #effective:r-x
default:group::r-x
default:group:sales:rwx #effective:r-x
default:mask::r-x
default:other::r-x
A. sales
B. bruce
C. all users
D. hdfs
E. user
Answer:
E
//askubuntu.com/questions/257896/what-is-meant-by-mask-and-effective-in-the-output-
from-getfacl
Question 10
Your customer wants you to set up ODI by using the IKM SQL to Hive module and overwrite existing
Hive tables with the customer’s new clinical dat
a.
What parameter must be set to true?
- A. SQOOP_ODI_OVERWRITE
- B. OVERWRITE_HIVE_TABLE
- C. OVERWRITE_HDFS_TABLE
- D. CREATE_HIVE_TABLE
Answer:
D
Question 11
Your customer wants to implement the Oracle Table Access for a Hadoop Connector (OTA4H) to
connect the Hadooop cluster to the Oracle database. The customer’s Oracle Database is a Real
Application Clusters database.
How should you configure the database listener?
A. The database listener is configured to route requests to the designated "hadoop" node in the
listener’s service definition.
B. The database listener is configured to route the Hadoop connection requests to the available
nodes randomly, provided that the RAC-aware service name is specified in the JDBC URL.
C. The database listener is configured to route the Hadoop connection requests to the first node the
RAC cluster because clustered environments are not inherently supported.
D. Connecting to a RAC database is not supported.
Answer:
B
Oracle RAC Awareness
JDBC and UCP are aware of various Oracle RAC instances. This can be used to split queries submitted
to JDBC. The StorageHandler will depend on listener for load balancing.
//docs.oracle.com/cd/E65728_01/doc.43/e65665/GUID-C2A509A4-34CB-4B58-AC55-
6CCCE51163A8.htm#BIGUG-GUID-A49A8B7F-34A2-4999-8610-9C3A1F1D453A
Question 12
Your customer has a Big Data Appliance and an Exadata Database Machine and would like to extend
security. Select two ways that security works in Big Data SQL. (Choose two.)
A. On the Big Data Appliance, Hadoop's native security is used.
B. On the Exadata Database Machine, Oracle Advanced Security is used for fine-grained access
control.
C. On the Big Data Appliance, Oracle Advanced Hadoop Security is used for fine grained access
control.
D. On the Big Data Appliance, Oracle Identity Management is used.
E. On the Big Data Appliance, data is encrypted by using Oracle Transparent Data Encryption (TDE).
Answer:
B,E
Transparent Data Encryption is a great way to protect sensitive data in large-scale Exadata scenarios.
With Exadata, substantial crypto performance gains are possible.
Oracle Exadata Database Machine with Oracle Advanced Security
Oracle Advanced Security transparent data encryption (TDE) protects sensitive data such as
credit card numbers and email addresses from attempts to access at the operating system
level, on backup media or in database exports. No triggers, views or other costly changes to
the application are required. TDE leverages performance and storage optimizations of the
Oracle Exadata Database Machine, including the Smart Flash Cache and Hybrid Columnar
Compression (EHCC).
//www.oracle.com/us/products/database/exadata-db-machine-security-ds-401799.pdf
Question 13
Your customer has had a security breach on its running Big Data Appliance and needs to quickly
enable security for Hive and Impal
a.
What is the quickest way to enable the Sentry service?
A. Execute bdacli sentry enable.
B. Use the Mammoth utility during installation.
C. Sentry is enabled by default on the Big Data Appliance.
D. Use the Cloudera Manager.
Answer:
D
Sentry Setup with Hive.
Before Sentry is setup we have to ensure that Kerberos is enabled in the cluster and users have
Question 14
What are two reasons that a MapReduce job is not run when the following command is executed in
Hive? (Choose two.)
hive> create view v_consolidated_credit_products as select
hcd.customer_id, hcd.credit_card_limits, hcd.credit_balance, hmd
a.n_mortgages, hmda.mortgage_amount
from mortgages_department_agg hmda join credit_department hcd on
hcd.customer_id=hmda.customer_id;
OK
Time taken: 0.316 seconds
A. The MapReduce job is run when the view is accessed.
B. MapReduce is run; the command output is incorrect.
C. MapReduce is not run with Hive. Hive bypasses the MapReduce layer.
D. A view only defines the metadata in the RDBMS store.
E. MapReduce is run in the background.
Answer:
A,D
The CREATE VIEW statement lets you create a shorthand abbreviation for a more complicated query.
The base query can involve joins, expressions, reordered columns, column aliases, and other SQL
features that can make a query hard to understand or maintain.
Because a view is purely a logical construct (an alias for a query) with no physical data behind it,
ALTER VIEW only involves changes to metadata in the metastore database, not any data files in HDFS.
//www.cloudera.com/documentation/enterprise/5-6-x/topics/impala_create_view.html
Question 15
Your customer needs to access Hive tables, HDFS, and Data Pump format files as the data source.
When installing and configuring the Oracle SQL Connector for HDFS, which two locations must be
installed or configured to fulfill this requirement? (Choose two.)
A. Hadoop cluster
B. HiveQL
C. Impala
D. Oracle database
E. Oracle NoSQL
Answer:
A,D
Using Oracle SQL Connector for HDFS, you can use Oracle Database to access and analyze data
//docs.oracle.com/cd/E37231_01/doc.20/e36961/sqlch.htm#BDCUG126