microsoft AI-102 Exam Questions
Questions for the AI-102 were updated on : Jun 25 ,2025
Page 1 out of 8. Viewing questions 1-15 out of 112
Question 1 Topic 1, Case Study 1Case Study Question View Case
DRAG DROP
You are planning the product creation project.
You need to recommend a process for analyzing videos.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the
answer area and arrange them in the correct order. (Choose four.)
Select and Place:
Answer:

Explanation:
Scenario: All videos must have transcripts that are associated to the video and included in product descriptions. Product
descriptions, transcripts, and all text must be available in English, Spanish, and Portuguese.
Step 1: Upload the video to blob storage
Given a video or audio file, the file is first dropped into a Blob Storage. T
Step 2: Index the video by using the Video Indexer API.
When a video is indexed, Video Indexer produces the JSON content that contains details of the specified video insights. The
insights include: transcripts, OCRs, faces, topics, blocks, etc.
Step 3: Extract the transcript from the Video Indexer API.
Step 4: Translate the transcript by using the Translator API.
Reference: https://azure.microsoft.com/en-us/blog/get-video-insights-in-even-more-languages/
https://docs.microsoft.com/en-us/azure/media-services/video-indexer/video-indexer-output-json-v2 Implement Natural
Language Processing Solutions
Question 2 Topic 1, Case Study 1Case Study Question View Case
HOTSPOT
You need to develop code to upload images for the product creation project. The solution must meet the accessibility
requirements.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Explanation:
Reference: https://github.com/Azure-Samples/cognitive-services-dotnet-sdk-samples/blob/master/documentation-
samples/quickstarts/ComputerVision/Program.cs
Question 3 Topic 2, Case Study 2Case Study Question View Case
DRAG DROP
You are developing a solution for the Management-Bookkeepers group to meet the document processing requirements. The
solution must contain the following components:
A From Recognizer resource
An Azure web app that hosts the Form Recognizer sample labeling tool
The Management-Bookkeepers group needs to create a custom table extractor by using the sample labeling tool.
Which three actions should the Management-Bookkeepers group perform in sequence? To answer, move the appropriate
cmdlets from the list of cmdlets to the answer area and arrange them in the correct order.
Select and Place: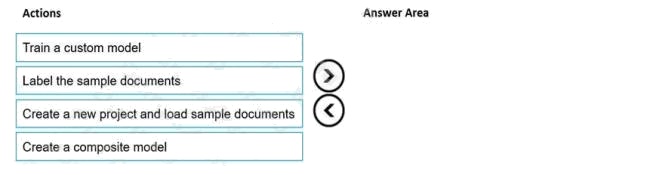
Answer:
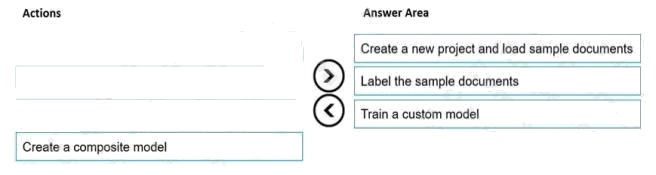
Explanation:
Step 1: Create a new project and load sample documents
Create a new project. Projects store your configurations and settings.
Step 2: Label the sample documents
When you create or open a project, the main tag editor window opens.
Step 3: Train a custom model. Finally, train a custom model.
Reference: https://docs.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/label-tool
Question 4 Topic 2, Case Study 2Case Study Question View Case
You are developing the knowledgebase.
You use Azure Video Analyzer for Media (previously Video indexer) to obtain transcripts of webinars.
You need to ensure that the solution meets the knowledgebase requirements.
What should you do?
- A. Create a custom language model
- B. Configure audio indexing for videos only
- C. Enable multi-language detection for videos
- D. Build a custom Person model for webinar presenters
Answer:
B
Explanation:
Can search content in different formats, including video
Audio and video insights (multi-channels). When indexing by one channel, partial result for those models will be available.
Keywords extraction: Extracts keywords from speech and visual text.
Named entities extraction: Extracts brands, locations, and people from speech and visual text via natural language
processing (NLP).
Topic inference: Makes inference of main topics from transcripts. The 2nd-level IPTC taxonomy is included.
Artifacts: Extracts rich set of "next level of details" artifacts for each of the models.
Sentiment analysis: Identifies positive, negative, and neutral sentiments from speech and visual text.
Incorrect Answers:
C: Webinars Videos are in English.
Reference: https://docs.microsoft.com/en-us/azure/azure-video-analyzer/video-analyzer-for-media-docs/video-indexer-
overview
Question 5 Topic 3, Case Study 3Case Study Question View Case
You are developing the document processing workflow.
You need to identify which API endpoints to use to extract text from the financial documents. The solution must meet the
document processing requirements.
Which two API endpoints should you identify? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. /vision/v3.1/read/analyzeResults
- B. /formrecognizer/v2.0/custom/models/{modelId}/analyze
- C. /formrecognizer/v2.0/prebuilt/receipt/analyze
- D. /vision/v3.1/describe
- E. /vision/v3.1/read/analyze
Answer:
C E
Explanation:
C: Analyze Receipt - Get Analyze Receipt Result.
Query the status and retrieve the result of an Analyze Receipt operation.
Request URL: https://{endpoint}/formrecognizer/v2.0-preview/prebuilt/receipt/analyzeResults/{resultId}
E: POST {Endpoint}/vision/v3.1/read/analyze
Use this interface to get the result of a Read operation, employing the state-of-the-art Optical Character Recognition (OCR)
algorithms optimized for text-heavy documents.
Scenario: Contoso plans to develop a document processing workflow to extract information automatically from PDFs and
images of financial documents The document processing solution must be able to process standardized financial
documents that have the following characteristics: - Contain fewer than 20 pages.
- Be formatted as PDF or JPEG files.
- Have a distinct standard for each office.
*The document processing solution must be able to extract tables and text from the financial documents. The document

processing solution must be able to extract information from receipt images.
Reference: https://westus2.dev.cognitive.microsoft.com/docs/services/form-recognizer-api-v2-
preview/operations/GetAnalyzeReceiptResult https://docs.microsoft.com/en-us/rest/api/computervision/3.1/read/read
Question 6 Topic 3, Case Study 3Case Study Question View Case
HOTSPOT
You are developing the knowledgebase by using Azure Cognitive Search.
You need to build a skill that will be used by indexers.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Explanation:
Box 1: "categories": ["Locations", "Persons", "Organizations"], Locations, Persons, Organizations are in the outputs.
Scenario: Contoso plans to develop a searchable knowledgebase of all the intellectual property Note: The categories
parameter is an array of categories that should be extracted. Possible category types: "Person", "Location", "Organization",
"Quantity", "Datetime", "URL", "Email". If no category is provided, all types are returned.
Box 2: {"name": " entities"}
The include wikis, so should include entities in the outputs.
Note: entities is an array of complex types that contains rich information about the entities extracted from text, with the
following fields name (the actual entity name. This represents a "normalized" form) wikipediaId
wikipediaLanguage
wikipediaUrl (a link to Wikipedia page for the entity) etc.
Reference: https://docs.microsoft.com/en-us/azure/search/cognitive-search-skill-entity-recognition
Question 7 Topic 3, Case Study 3Case Study Question View Case
You are developing the knowledgebase by using Azure Cognitive Search.
You need to process wiki content to meet the technical requirements.
What should you include in the solution?
- A. an indexer for Azure Blob storage attached to a skillset that contains the language detection skill and the text translation skill
- B. an indexer for Azure Blob storage attached to a skillset that contains the language detection skill
- C. an indexer for Azure Cosmos DB attached to a skillset that contains the document extraction skill and the text translation skill
- D. an indexer for Azure Cosmos DB attached to a skillset that contains the language detection skill and the text translation skill
Answer:
C
Explanation:
The wiki contains text in English, French and Portuguese.
Scenario: All planned projects must support English, French, and Portuguese.
The Document Extraction skill extracts content from a file within the enrichment pipeline. This allows you to take advantage
of the document extraction step that normally happens before the skillset execution with files that may be generated by other
skills.
Note: The Translator Text API will be used to determine the from language. The Language detection skill is not required.
Incorrect Answers:
Not A, not B: The wiki is stored in Azure Cosmos DB.
Reference:
https://docs.microsoft.com/en-us/azure/search/cognitive-search-skill-document-extraction https://docs.microsoft.com/en-
us/azure/search/cognitive-search-skill-text-translation
Question 8 Topic 3, Case Study 3Case Study Question View Case
You are developing the knowledgebase by using Azure Cognitive Search.
You need to meet the knowledgebase requirements for searching equivalent terms.
What should you include in the solution?
- A. synonym map
- B. a suggester
- C. a custom analyzer
- D. a built-in key phrase extraction skill
Answer:
A
Explanation:
Within a search service, synonym maps are a global resource that associate equivalent terms, expanding the scope of a
query without the user having to actually provide the term. For example, assuming "dog", "canine", and "puppy" are mapped
synonyms, a query on "canine" will match on a document containing "dog".
Create synonyms: A synonym map is an asset that can be created once and used by many indexes.
Reference: https://docs.microsoft.com/en-us/azure/search/search-synonyms
Question 9 Topic 4, Case Study 4Case Study Question View Case
HOTSPOT
You are developing the shopping on-the-go project.
You need to build the Adaptive Card for the chatbot.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Explanation:
Box 1: name [language]
Chatbot must support interactions in English, Spanish, and Portuguese.
Box 2: "$when:${stockLevel != 'OK'}"
Product displays must include images and warnings when stock levels are low or out of stock.
Box 3: image.altText[language]
Question 10 Topic 4, Case Study 4Case Study Question View Case
HOTSPOT
You are developing the shopping on-the-go project.
You are configuring access to the QnA Maker resources.
Which role should you assign to AllUsers and LeadershipTeam? To answer, select the appropriate options in the answer
area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Explanation:
Box 1: QnA Maker Editor
Scenario: Provide all employees with the ability to edit Q&As.
The QnA Maker Editor (read/write) has the following permissions:
Create KB API
Update KB API
Replace KB API
Replace Alterations
"Train API" [in new service model v5]
Box 2: Contributor
Scenario: Only senior managers must be able to publish updates. Contributor permission: All except ability to add new
members to roles
Reference: https://docs.microsoft.com/en-us/azure/cognitive-services/qnamaker/reference-role-based-access-control
Question 11 Topic 4, Case Study 4Case Study Question View Case
HOTSPOT
You are developing the shopping on-the-go project.
You need to build the Adaptive Card for the chatbot.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Explanation:
Box 1: name.en
Box 2: "$when": "${stockLevel != 'OK'}"
Product displays must include images and warnings when stock levels are low or out of stock.
Box 3:image.altText.en
Question 12 Topic 5, Case Study 5Case Study Question View Case
You are developing the chatbot.
You create the following components:
A QnA Maker resource
A chatbot by using the Azure Bot Framework SDK
You need to integrate the components to meet the chatbot requirements.
Which property should you use?
- A. QnAMakerOptions.StrictFilters
- B. QnADialogResponseOptions.CardNoMatchText
- C. QnAMakerOptions.RankerType
- D. QnAMakerOptions.ScoreThreshold
Answer:
C
Explanation:
Scenario: When the response confidence score is low, ensure that the chatbot can provide other response options to the
customers.
When no good match is found by the ranker, the confidence score of 0.0 or "None" is returned and the default response is
"No good match found in the KB". You can override this default response in the bot or application code calling the endpoint.
Alternately, you can also set the override response in Azure and this changes the default for all knowledge bases deployed
in a particular QnA Maker service.
Choosing Ranker type: By default, QnA Maker searches through questions and answers. If you want to search through
questions only, to generate an answer, use the RankerType=QuestionOnly in the POST body of the GenerateAnswer
request.
Reference: https://docs.microsoft.com/en-us/azure/cognitive-services/qnamaker/concepts/best-practices
Question 13 Topic 5, Case Study 5Case Study Question View Case
You are developing the chatbot.
You create the following components:
A QnA Maker resource
A chatbot by using the Azure Bot Framework SDK
You need to add an additional component to meet the technical requirements and the chatbot requirements.
What should you add?
- A. Microsoft Translator
- B. Language Understanding
- C. Dispatch
- D. chatdown
Answer:
C
Explanation:
Scenario: All planned projects must support English, French, and Portuguese.
If a bot uses multiple LUIS models and QnA Maker knowledge bases (knowledge bases), you can use the Dispatch tool to
determine which LUIS model or QnA Maker knowledge base best matches the user input. The dispatch tool does this by
creating a single LUIS app to route user input to the correct model.
Reference:
https://docs.microsoft.com/en-us/azure/bot-service/bot-builder-tutorial-dispatch
Question 14 Topic 6, Mixed Questions
DRAG DROP
You have 100 chatbots that each has its own Language Understanding model.
Frequently, you must add the same phrases to each model.
You need to programmatically update the Language Understanding models to include the new phrases.
How should you complete the code? To answer, drag the appropriate values to the correct targets. Each value may be used
once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place: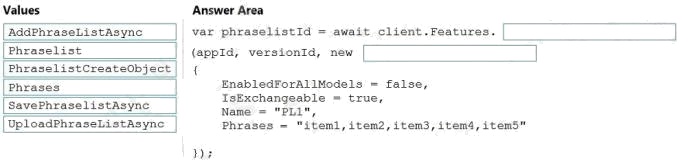
Answer:

Explanation:
Box 1: AddPhraseListAsync Example: Add phraselist feature
var phraselistId = await client.Features.AddPhraseListAsync(appId, versionId, new PhraselistCreateObject
{
EnabledForAllModels = false,
IsExchangeable = true,
Name = "QuantityPhraselist",
Phrases = "few,more,extra" });
Box 2: PhraselistCreateObject
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/luis/client-libraries-rest-api
Question 15 Topic 6, Mixed Questions
DRAG DROP
You plan to use a Language Understanding application named app1 that is deployed to a container.
App1 was developed by using a Language Understanding authoring resource named lu1.
App1 has the versions shown in the following table.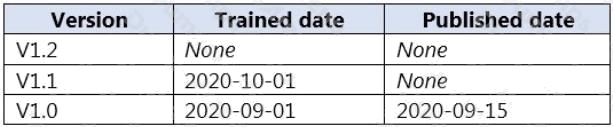
You need to create a container that uses the latest deployable version of app1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the
answer area and arrange them in the correct order. (Choose three.)
Select and Place:
Answer:
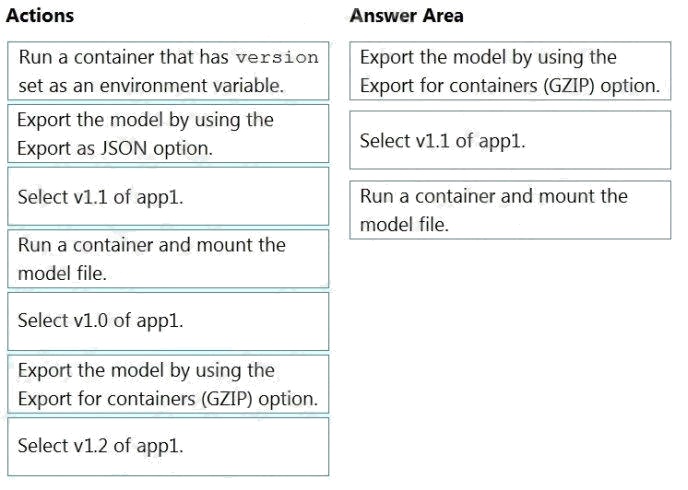
Explanation:
Step 1: Export the model using the Export for containers (GZIP) option.
1. Sign on to the LUIS portal.
2. Select the app in the list.
3. Select Manage in the app's navigation bar.
5. Select the checkbox to the left of the version name in the list.
6. Select the Export item from the contextual toolbar above the list.
7. Select Export for container (GZIP).
8. The package is downloaded from the browser.
Step 2: Select v1.1 of app1.
A trained or published app packaged as a mounted input to the container with its associated App ID.
Step 3: Run a contain and mount the model file.
Run the container, with the required input mount and billing settings.
Reference: https://docs.microsoft.com/en-us/azure/cognitive-services/luis/luis-container-howto