google PROFESSIONAL MACHINE LEARNING ENGINEER Exam Questions
Questions for the PROFESSIONAL MACHINE LEARNING ENGINEER were updated on : Jul 11 ,2025
Page 1 out of 4. Viewing questions 1-15 out of 60
Question 1
Your team has been tasked with creating an ML solution in Google Cloud to classify support requests for one of your
platforms. You analyzed the requirements and decided to use TensorFlow to build the classifier so that you have full control
of the models code, serving, and deployment. You will use Kubeflow pipelines for the ML platform. To save time, you want
to build on existing resources and use managed services instead of building a completely new model. How should you build
the classifier?
- A. Use the Natural Language API to classify support requests.
- B. Use AutoML Natural Language to build the support requests classifier.
- C. Use an established text classification model on AI Platform to perform transfer learning.
- D. Use an established text classification model on AI Platform as-is to classify support requests.
Answer:
D
Question 2
You are responsible for building a unified analytics environment across a variety of on-premises data marts. Your company
is experiencing data quality and security challenges when integrating data across the servers, caused by the use of a wide
range of disconnected tools and temporary solutions. You need a fully managed, cloud-native data integration service that
will lower the total cost of work and reduce repetitive work. Some members on your team prefer a codeless interface for
building Extract, Transform, Load (ETL) process. Which service should you use?
- A. Dataflow
- B. Dataprep
- C. Apache Flink
- D. Cloud Data Fusion
Answer:
D
Question 3
Your team is working on an NLP research project to predict political affiliation of authors based on articles they have written.
You have a large training dataset that is structured like this:
You followed the standard 80%-10%-10% data distribution across the training, testing, and evaluation subsets. How should
you distribute the training examples across the train-test-eval subsets while maintaining the 80-10-10 proportion?
- A. Distribute texts randomly across the train-test-eval subsets: Train set: [TextA1, TextB2, ...] Test set: [TextA2, TextC1, TextD2, ...] Eval set: [TextB1, TextC2, TextD1, ...]
- B. Distribute authors randomly across the train-test-eval subsets: (*) Train set: [TextA1, TextA2, TextD1, TextD2, ...] Test set: [TextB1, TextB2, ...] Eval set: [TexC1,TextC2 ...]
- C. Distribute sentences randomly across the train-test-eval subsets: Train set: [SentenceA11, SentenceA21, SentenceB11, SentenceB21, SentenceC11, SentenceD21 ...] Test set: [SentenceA12, SentenceA22, SentenceB12, SentenceC22, SentenceC12, SentenceD22 ...] Eval set: [SentenceA13, SentenceA23, SentenceB13, SentenceC23, SentenceC13, SentenceD31 ...]
- D. Distribute paragraphs of texts (i.e., chunks of consecutive sentences) across the train-test-eval subsets: Train set: [SentenceA11, SentenceA12, SentenceD11, SentenceD12 ...] Test set: [SentenceA13, SentenceB13, SentenceB21, SentenceD23, SentenceC12, SentenceD13 ...] Eval set: [SentenceA11, SentenceA22, SentenceB13, SentenceD22, SentenceC23, SentenceD11 ...]
Answer:
C
Question 4
You are training a deep learning model for semantic image segmentation with reduced training time. While using a Deep
Learning VM Image, you receive the following error: The resource 'projects/deeplearning-platforn/zones/europe-west4-
c/acceleratorTypes/nvidia-tesla-k80' was not found. What should you do?
- A. Ensure that you have GPU quota in the selected region.
- B. Ensure that the required GPU is available in the selected region.
- C. Ensure that you have preemptible GPU quota in the selected region.
- D. Ensure that the selected GPU has enough GPU memory for the workload.
Answer:
A
Question 5
Your team needs to build a model that predicts whether images contain a drivers license, passport, or credit card. The data
engineering team already built the pipeline and generated a dataset composed of 10,000 images with drivers licenses,
1,000 images with passports, and 1,000 images with credit cards. You now have to train a model with the following label
map: [drivers_license, passport, credit_card]. Which loss function should you use?
- A. Categorical hinge
- B. Binary cross-entropy
- C. Categorical cross-entropy
- D. Sparse categorical cross-entropy
Answer:
D
Explanation:
se sparse_categorical_crossentropy. Examples for above 3-class classification problem: [1] , [2], [3]
Reference: https://stats.stackexchange.com/questions/326065/cross-entropy-vs-sparse-cross-entropy-when-to-use-one-
over-the-other
Question 6
Your team trained and tested a DNN regression model with good results. Six months after deployment, the model is
performing poorly due to a change in the distribution of the input data. How should you address the input differences in
production?
- A. Create alerts to monitor for skew, and retrain the model.
- B. Perform feature selection on the model, and retrain the model with fewer features.
- C. Retrain the model, and select an L2 regularization parameter with a hyperparameter tuning service.
- D. Perform feature selection on the model, and retrain the model on a monthly basis with fewer features.
Answer:
C
Question 7
You were asked to investigate failures of a production line component based on sensor readings. After receiving the dataset,
you discover that less than 1% of the readings are positive examples representing failure incidents. You have tried to train
several classification models, but none of them converge. How should you resolve the class imbalance problem?
- A. Use the class distribution to generate 10% positive examples.
- B. Use a convolutional neural network with max pooling and softmax activation.
- C. Downsample the data with upweighting to create a sample with 10% positive examples.
- D. Remove negative examples until the numbers of positive and negative examples are equal.
Answer:
B
Explanation:
Reference: https://towardsdatascience.com/convolution-neural-networks-a-beginners-guide-implementing-a-mnist-hand-
written-digit-8aa60330d022
Question 8
You need to design a customized deep neural network in Keras that will predict customer purchases based on their
purchase history. You want to explore model performance using multiple model architectures, store training data, and be
able to compare the evaluation metrics in the same dashboard. What should you do?
- A. Create multiple models using AutoML Tables.
- B. Automate multiple training runs using Cloud Composer.
- C. Run multiple training jobs on AI Platform with similar job names.
- D. Create an experiment in Kubeflow Pipelines to organize multiple runs.
Answer:
C
Question 9
You are developing a Kubeflow pipeline on Google Kubernetes Engine. The first step in the pipeline is to issue a query
against BigQuery. You plan to use the results of that query as the input to the next step in your pipeline. You want to achieve
this in the easiest way possible. What should you do?
- A. Use the BigQuery console to execute your query, and then save the query results into a new BigQuery table.
- B. Write a Python script that uses the BigQuery API to execute queries against BigQuery. Execute this script as the first step in your Kubeflow pipeline.
- C. Use the Kubeflow Pipelines domain-specific language to create a custom component that uses the Python BigQuery client library to execute queries.
- D. Locate the Kubeflow Pipelines repository on GitHub. Find the BigQuery Query Component, copy that components URL, and use it to load the component into your pipeline. Use the component to execute queries against BigQuery.
Answer:
A
Question 10
You work on a growing team of more than 50 data scientists who all use AI Platform. You are designing a strategy to
organize your jobs, models, and versions in a clean and scalable way. Which strategy should you choose?
- A. Set up restrictive IAM permissions on the AI Platform notebooks so that only a single user or group can access a given instance.
- B. Separate each data scientists work into a different project to ensure that the jobs, models, and versions created by each data scientist are accessible only to that user.
- C. Use labels to organize resources into descriptive categories. Apply a label to each created resource so that users can filter the results by label when viewing or monitoring the resources.
- D. Set up a BigQuery sink for Cloud Logging logs that is appropriately filtered to capture information about AI Platform resource usage. In BigQuery, create a SQL view that maps users to the resources they are using
Answer:
A
Question 11
You work for a large hotel chain and have been asked to assist the marketing team in gathering predictions for a targeted
marketing strategy. You need to make predictions about user lifetime value (LTV) over the next 20 days so that marketing
can be adjusted accordingly. The customer dataset is in BigQuery, and you are preparing the tabular data for training with
AutoML Tables. This data has a time signal that is spread across multiple columns. How should you ensure that AutoML fits
the best model to your data?
- A. Manually combine all columns that contain a time signal into an array. AIlow AutoML to interpret this array appropriately. Choose an automatic data split across the training, validation, and testing sets.
- B. Submit the data for training without performing any manual transformations. AIlow AutoML to handle the appropriate transformations. Choose an automatic data split across the training, validation, and testing sets.
- C. Submit the data for training without performing any manual transformations, and indicate an appropriate column as the Time column. AIlow AutoML to split your data based on the time signal provided, and reserve the more recent data for the validation and testing sets.
- D. Submit the data for training without performing any manual transformations. Use the columns that have a time signal to manually split your data. Ensure that the data in your validation set is from 30 days after the data in your training set and that the data in your testing sets from 30 days after your validation set.
Answer:
D
Question 12
You have trained a deep neural network model on Google Cloud. The model has low loss on the training data, but is
performing worse on the validation data. You want the model to be resilient to overfitting. Which strategy should you use
when retraining the model?
- A. Apply a dropout parameter of 0.2, and decrease the learning rate by a factor of 10.
- B. Apply a L2 regularization parameter of 0.4, and decrease the learning rate by a factor of 10.
- C. Run a hyperparameter tuning job on AI Platform to optimize for the L2 regularization and dropout parameters.
- D. Run a hyperparameter tuning job on AI Platform to optimize for the learning rate, and increase the number of neurons by a factor of 2.
Answer:
D
Question 13
Your organizations call center has asked you to develop a model that analyzes customer sentiments in each call. The call
center receives over one million calls daily, and data is stored in Cloud Storage. The data collected must not leave the region
in which the call originated, and no Personally Identifiable Information (PII) can be stored or analyzed. The data science
team has a thirdparty tool for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to
select components for data processing and for analytics. How should the data pipeline be designed?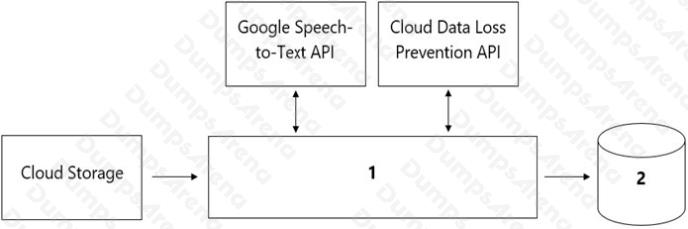
- A. 1= Dataflow, 2= BigQuery
- B. 1 = Pub/Sub, 2= Datastore
- C. 1 = Dataflow, 2 = Cloud SQL
- D. 1 = Cloud Function, 2= Cloud SQL
Answer:
B
Question 14
You are training a Resnet model on AI Platform using TPUs to visually categorize types of defects in automobile engines.
You capture the training profile using the Cloud TPU profiler plugin and observe that it is highly input-bound. You want to
reduce the bottleneck and speed up your model training process. Which modifications should you make to the tf.data
dataset? (Choose two.)
- A. Use the interleave option for reading data.
- B. Reduce the value of the repeat parameter.
- C. Increase the buffer size for the shuttle option.
- D. Set the prefetch option equal to the training batch size.
- E. Decrease the batch size argument in your transformation.
Answer:
A E
Question 15
You built and manage a production system that is responsible for predicting sales numbers. Model accuracy is crucial,
because the production model is required to keep up with market changes. Since being deployed to production, the model
hasnt changed; however the accuracy of the model has steadily deteriorated. What issue is most likely causing the steady
decline in model accuracy?
- A. Poor data quality
- B. Lack of model retraining
- C. Too few layers in the model for capturing information
- D. Incorrect data split ratio during model training, evaluation, validation, and test
Answer:
D