docker DCA Exam Questions
Questions for the DCA were updated on : Feb 20 ,2026
Page 1 out of 13. Viewing questions 1-15 out of 191
Question 1
Which statement is correct about cluster management in Docker Enterprise Edition 3.x?
- A. Clusters can contain Linux only.
- B. Clusters can contain Linux, Windows Server 2016 and 2019, and Linux on IBM z Systems.
- C. Clusters can contain Windows 10 and Windows Server 2016 only.
- D. Clusters can contain Linux and Windows Server 2008 R2 only.
Answer:
B
Question 2
Two pods bear the same label, app: dev.
Will a label selector matching app: dev match both of these pods?
- A. Yes, if the pods are in the same Kubernetes namespace as the object bearing the label selector.
- B. Yes, if the pods are in the same Kubernetes namespace as the object bearing the label selector and both pods were pre-existing when the label selector was declared.
- C. Yes, if both pods were pre-existing when the label selector was declared.
- D. Yes, as long as all the containers in those pods are passing their livenessProbes and readinessProbes.
Answer:
A
Question 3
When an application being managed by UCP fails, you would like a summary of all requests made to
the UCP API in the hours leading up to the failure.
What must be configured correctly beforehand for this to be possible?
- A. All engines in the cluster must have their log driver set to the 'metadata' or 'request' level.
- B. UCP logging levels must be set to the info' or debug' level.
- C. UCP audit logs must be set to the 'metadata' or 'request' level.
- D. Set the logging level in the config object for the ucp-kube-epi-server container to warning or higher
Answer:
C
Question 4
You set up an automatic pruning policy on a DTR repository to prune all images using Apache
licenses.
What effect does this have on images in this repository?
- A. Matching images are untagged during the next prune job.
- B. Matching images are deleted during the next prune job.
- C. Matching images are untagged once they are older than the pruning threshold set in the repository's Settings tab.
- D. Matching images are untagged during the next prune job, and subsequently deleted once they are older than the pruning threshold set in the repository's Settings tab.
Answer:
A
Question 5
Some Docker images take time to build through a Continuous Integration environment. You want to
speed up builds and take advantage of build caching.
Where should the most frequently changed part of a Docker image be placed in a Dockerfile?
- A. at the top of the Dockerfile
- B. after the FROM directive
- C. at the bottom of the Dockerfile
- D. in the ENTRYPOINT directive
Answer:
C
Question 6
How do you change the default logging driver for the docker daemon in Linux?
- A. Install a logging agent on the Linux host.
- B. Set the value of 'log-driver' to the name of the logging driver in the daemon.json in /etc/docker.
- C. Use the -log-driver1 flag when you run a container.
- D. At the command line, type: docker log driver set <driver name>
Answer:
B
Question 7
What is the difference between the ADD and COPY Dockerfile instructions? (Select two.)
- A. ADD supports remote URL handling while COPY does not.
- B. COPY supports compression format handling while ADD does not.
- C. COPY supports regular expression handling while ADD does not.
- D. ADD supports regular expression handling while COPY does not.
- E. ADD supports compression format handling while COPY does not.
Answer:
A,E
Question 8
Are these conditions sufficient for Kubernetes to dynamically provision a persistentVolume,
assuming there are no limitations on the amount and type of available external storage?
Solution: A volume is defined in a pod specification with the key persistentVolume: default.
- A. Yes
- B. No
Answer:
B
Question 9
A persistentVolumeClaim (PVC) is created with the specification storageClass: "".and size
requirements that cannot be satisfied by any existing persistentVolume.
Is this an action Kubernetes takes in this situation?
Solution: Kubernetes returns an error indicating that the PVC could not be bound with the current
resources.
- A. Yes
- B. No
Answer:
A
Question 10
Will this sequence of steps completely delete an image from disk in the Docker Trusted Registry?
Solution: Manually delete all layers used by the image on the disk from the Docker Trusted Registry.
- A. Yes
- B. No
Answer:
B
Question 11
Will a DTR security scan detect this?
Solution: known vulnerabilities or exposures in binaries
- A. Yes
- B. No
Answer:
A
Question 12
Will this configuration achieve fault tolerance for managers in a swarm?
Solution: at least seven nodes in total
- A. Yes
- B. No
Answer:
A
Question 13
The Kubernetes yaml shown below describes a networkPolicy.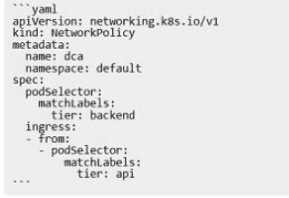
Will the networkPolicy BLOCK this trafftc?
Solution. a request issued from a pod bearing only the tier: frontend label, to a pod bearing the tier:
backend label
- A. Yes
- B. No
Answer:
A
Explanation:
The provided Kubernetes NetworkPolicy YAML configuration indicates that the policy applies to pods
with the label tier: backend in the default namespace1.The ingress rule allows traffic from pods with
the label tier: api1.Therefore, a request issued from a pod bearing only the tier:frontend label to a
pod bearing the tier: backend label will be blocked by this networkPolicy1.This is because the
networkPolicy does not have a rule allowing ingress from pods with the tier: frontend label1. For
more information on Kubernetes NetworkPolicies, you can refer to theKubernetes Documentation on
Network Policies.
Question 14
The Kubernetes yaml shown below describes a networkPolicy.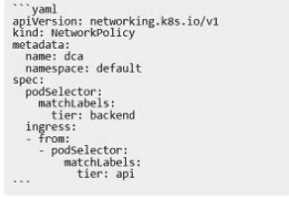
Will the networkPolicy BLOCK this trafftc?
Solution.a request issued from a pod bearing the tier: api label, to a pod bearing the tier: backend
label
- A. Yes
- B. No
Answer:
B
Explanation:
The provided Kubernetes NetworkPolicy YAML configuration indicates that the policy applies to pods
with the labeltier: backendin thedefaultnamespace1.The ingress rule allows traffic from pods with
the labeltier: api1.Therefore, a request issued from a pod bearing thetier: apilabel to a pod bearing
thetier: backendlabel will not be blocked by this networkPolicy1.This is because the networkPolicy
explicitly allows ingress from pods with thetier: apilabel1. For more information on Kubernetes
Network
Question 15
Will this configuration achieve fault tolerance for managers in a swarm?
Solution: one manager node for two worker nodes
- A. Yes
- B. No
Answer:
B
Explanation:
Docker Swarm requires more than one manager node to achieve fault tolerance12.A single manager
node is not fault tolerant because if it goes down, the entire cluster goes down3.For a swarm to be
fault-tolerant, it needs to have an odd number of manager nodes2.For example, a three-manager
swarm tolerates a maximum loss of one manager2.Therefore, a configuration with one manager
node for two worker nodes will not achieve fault tolerance for managers in a swarm12.