databricks DATABRICKS CERTIFIED DATA ENGINEER ASSOCIATE Exam Questions
Questions for the DATABRICKS CERTIFIED DATA ENGINEER ASSOCIATE were updated on : Feb 18 ,2026
Page 1 out of 8. Viewing questions 1-15 out of 109
Question 1
A data engineer needs to use a Delta table as part of a data pipeline, but they do not know if they
have the appropriate permissions.
In which location can the data engineer review their permissions on the table?
- A. Jobs
- B. Dashboards
- C. Catalog Explorer
- D. Repos
Answer:
C
Question 2
Which type of workloads are compatible with Auto Loader?
- A. Streaming workloads
- B. Machine learning workloads
- C. Serverless workloads
- D. Batch workloads
Answer:
A
Question 3
Which SQL keyword can be used to convert a table from a long format to a wide format?
- A. TRANSFORM
- B. PIVOT
- C. SUM
- D. CONVERT
Answer:
B
Question 4
Which two components function in the DB platform architecture’s control plane? (Choose two.)
- A. Virtual Machines
- B. Compute Orchestration
- C. Serverless Compute
- D. Compute
- E. Unity Catalog
Answer:
BE
Question 5
Identify the impact of ON VIOLATION DROP ROW and ON VIOLATION FAIL UPDATE for a constraint
violation.
A data engineer has created an ETL pipeline using Delta Live table to manage their company travel
reimbursement detail, they want to ensure that the if the location details has not been provided by
the employee, the pipeline needs to be terminated.
How can the scenario be implemented?
- A. CONSTRAINT valid_location EXPECT (location = NULL)
- B. CONSTRAINT valid_location EXPECT (location != NULL) ON VIOLATION FAIL UPDATE
- C. CONSTRAINT valid_location EXPECT (location != NULL) ON DROP ROW
- D. CONSTRAINT valid_location EXPECT (location != NULL) ON VIOLATION FAIL
Answer:
B
Question 6
Which method should a Data Engineer apply to ensure Workflows are being triggered on schedule?
- A. Scheduled Workflows require an always-running cluster, which is more expensive but reduces processing latency.
- B. Scheduled Workflows process data as it arrives at configured sources.
- C. Scheduled Workflows can reduce resource consumption and expense since the cluster runs only long enough to execute the pipeline.
- D. Scheduled Workflows run continuously until manually stopped.
Answer:
C
Question 7
Identify a scenario to use an external table.
A Data Engineer needs to create a parquet bronze table and wants to ensure that it gets stored in a
specific path in an external location.
Which table can be created in this scenario?
- A. An external table where the location is pointing to specific path in external location.
- B. An external table where the schema has managed location pointing to specific path in external location.
- C. A managed table where the catalog has managed location pointing to specific path in external location.
- D. A managed table where the location is pointing to specific path in external location.
Answer:
A
Question 8
Identify how the count_if function and the count where x is null can be used
Consider a table random_values with below data.
What would be the output of below query?
select count_if(col > 1) as count_
a. count(*) as count_b.count(col1) as count_c from random_values col1
NULL -
- A. 3 6 5
- B. 4 6 5
- C. 3 6 6
- D. 4 6 6
Answer:
A
Question 9
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data,
and then perform a streaming write into a new table.
The code block used by the data engineer is below:
Which line of code should the data engineer use to fill in the blank if the data engineer only wants
the query to execute a micro-batch to process data every 5 seconds?
- A. trigger("5 seconds")
- B. trigger(continuous="5 seconds")
- C. trigger(once="5 seconds")
- D. trigger(processingTime="5 seconds")
Answer:
D
Question 10
The Delta transaction log for the ‘students’ tables is shown using the ‘DESCRIBE HISTORY students’
command. A Data Engineer needs to query the table as it existed before the UPDATE operation listed
in the log.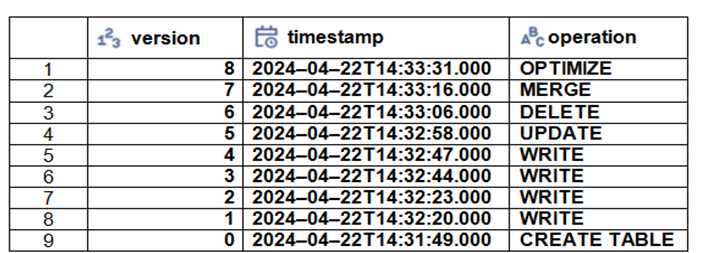
Which command should the Data Engineer use to achieve this? (Choose two.)
- A. SELECT * FROM students@v4
- B. SELECT * FROM students TIMESTAMP AS OF ‘2024-04-22T 14:32:47.000+00:00’
- C. SELECT * FROM students FROM HISTORY VERSION AS OF 3
- D. SELECT * FROM students VERSION AS OF 5
- E. SELECT * FROM students TIMESTAMP AS OF ‘2024-04-22T 14:32:58.000+00:00’
Answer:
AB
Question 11
A new data engineering team team has been assigned to an ELT project. The new data engineering
team will need full privileges on the table sales to fully manage the project.
Which command can be used to grant full permissions on the database to the new data engineering
team?
- A. grant all privileges on table sales TO team;
- B. GRANT SELECT ON TABLE sales TO team;
- C. GRANT SELECT CREATE MODIFY ON TABLE sales TO team;
- D. GRANT ALL PRIVILEGES ON TABLE team TO sales;
Answer:
A
Explanation:
To grant full privileges on a table such as 'sales' to a group like 'team', the correct SQL command in
Databricks is:
GRANT ALL PRIVILEGES ON TABLE sales TO team;
This command assigns all available privileges, including SELECT, INSERT, UPDATE, DELETE, and any
other data manipulation or definition actions, to the specified team. This is typically necessary when
a team needs full control over a table to manage and manipulate it as part of a project or ongoing
maintenance.
Reference:
Databricks documentation on SQL permissions: SQL Permissions in Databricks
Question 12
A data engineer needs access to a table new_uable, but they do not have the correct permissions.
They can ask the table owner for permission, but they do not know who the table owner is.
Which approach can be used to identify the owner of new_table?
A.
There is no way to identify the owner of the table
B.
Review the Owner field in the table's page in the cloud storage solution
C.
Review the Permissions tab in the table's page in Data Explorer
D.
Review the Owner field in the table’s page in Data Explorer
Answer:
D
Explanation:
To find the owner of a table in Databricks, one can utilize the Data Explorer feature. The Data
Explorer provides detailed information about various data objects, including tables. By navigating to
the specific table's page in Data Explorer, a data engineer can review the Owner field, which
identifies the individual or role that owns the table. This information is crucial for obtaining the
necessary permissions or for any administrative actions related to the table.
Reference:
Databricks documentation on Data Explorer: Using Data Explorer in Databricks
Question 13
A data engineer wants to schedule their Databricks SQL dashboard to refresh every hour, but they
only want the associated SQL endpoint to be running when It is necessary. The dashboard has
multiple queries on multiple datasets associated with it. The data that feeds the dashboard is
automatically processed using a Databricks Job.
Which approach can the data engineer use to minimize the total running time of the SQL endpoint
used in the refresh schedule of their dashboard?
- A. O They can reduce the cluster size of the SQL endpoint.
- B. Q They can turn on the Auto Stop feature for the SQL endpoint.
- C. O They can set up the dashboard's SQL endpoint to be serverless.
- D. 0 They can ensure the dashboard's SQL endpoint matches each of the queries' SQL endpoints.
Answer:
B
Explanation:
To minimize the total running time of the SQL endpoint used in the refresh schedule of a dashboard
in Databricks, the most effective approach is to utilize the Auto Stop feature. This feature allows the
SQL endpoint to automatically stop after a period of inactivity, ensuring that it only runs when
necessary, such as during the dashboard refresh or when actively queried. This minimizes resource
usage and associated costs by ensuring the SQL endpoint is not running idle outside of these
operations.
Reference:
Databricks documentation on SQL endpoints: SQL Endpoints in Databricks
Question 14
A data engineer and data analyst are working together on a data pipeline. The data engineer is
working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is
working on the gold layer of the pipeline using SQL The raw source of the pipeline is a streaming
input. They now want to migrate their pipeline to use Delta Live Tables.
Which change will need to be made to the pipeline when migrating to Delta Live Tables?
- A. The pipeline can have different notebook sources in SQL & Python.
- B. The pipeline will need to be written entirely in SQL.
- C. The pipeline will need to be written entirely in Python.
- D. The pipeline will need to use a batch source in place of a streaming source.
Answer:
A
Explanation:
When migrating to Delta Live Tables (DLT) with a data pipeline that involves different programming
languages across various data layers, the migration does not require unifying the pipeline into a
single language. Delta Live Tables support multi-language pipelines, allowing data engineers and
data analysts to work in their preferred languages, such as Python for data engineering tasks (raw,
bronze, and silver layers) and SQL for data analytics tasks (gold layer). This capability is particularly
beneficial in collaborative settings and leverages the strengths of each language for different stages
of data processing.
Reference:
Databricks documentation on Delta Live Tables: Delta Live Tables Guide
Question 15
A Delta Live Table pipeline includes two datasets defined using streaming live table. Three datasets
are defined against Delta Lake table sources using live table.
The table is configured to run in Production mode using the Continuous Pipeline Mode.
What is the expected outcome after clicking Start to update the pipeline assuming previously
unprocessed data exists and all definitions are valid?
A.
All datasets will be updated once and the pipeline will shut down. The compute resources
will be terminated.
B.
All datasets will be updated at set intervals until the pipeline is shut down. The compute
resources will persist to allow for additional testing.
C.
All datasets will be updated once and the pipeline will shut down. The compute resources
will persist to allow for additional testing.
D.
All datasets will be updated at set intervals until the pipeline is shut down. The compute
resources will be deployed for the update and terminated when the pipeline is stopped.
Answer:
D
Explanation:
In Delta Live Tables (DLT), when configured to run in Continuous Pipeline Mode, particularly in a
production environment, the system is designed to continuously process and update data as it
becomes available. This mode keeps the compute resources active to handle ongoing data
processing and automatically updates all datasets defined in the pipeline at predefined intervals.
Once the pipeline is manually stopped, the compute resources are terminated to conserve resources
and reduce costs. This mode is suitable for production environments where datasets need to be kept
up-to-date with the latest data.
Reference:
Databricks documentation on Delta Live Tables: Delta Live Tables Guide