databricks DATABRICKS CERTIFIED DATA ANALYST ASSOCIATE Exam Questions
Questions for the DATABRICKS CERTIFIED DATA ANALYST ASSOCIATE were updated on : Feb 18 ,2026
Page 1 out of 5. Viewing questions 1-15 out of 65
Question 1
Query History provides Databricks SQL users with a lot of benefits. A data analyst has been asked to
share all of these benefits with their team as part of a training exercise. One of the benefit
statements the analyst provided to their team is incorrect.
Which statement about Query History is incorrect?
- A. It can be used to view the query plan of queries that have run.
- B. It can be used to debug queries.
- C. It can be used to automate query execution on multiple warehouses (formerly endpoints).
- D. It can be used to troubleshoot slow running queries.
Answer:
C
Explanation:
Query History in Databricks SQL is intended for reviewing executed queries, understanding their
execution plans, and identifying performance issues or errors for debugging purposes. It allows users
to analyze query duration, resources used, and potential bottlenecks. However, Query History does
not provide any capability to automate the execution of queries across multiple warehouses;
automation must be handled through jobs or external orchestration tools, not through the Query
History feature itself.
Question 2
A data analyst has created a Query in Databricks SQL, and now wants to create two data
visualizations from that Query and add both of those data visualizations to the same Databricks SQL
Dashboard.
Which step will the data analyst need to take when creating and adding both data visualizations to
the Databricks SQL Dashboard?
- A. Copy the Query and create one data visualization per query.
- B. Add two separate visualizations to the dashboard based on the same Query.
- C. Decide on a single data visualization to add to the dashboard.
- D. Alter the Query to return two separate sets of results.
Answer:
B
Explanation:
Databricks SQL allows you to create multiple visualizations from a single query result. These
visualizations can be customized independently and each can be added to a dashboard. This feature
is explicitly supported and recommended in Databricks’ documentation on dashboards and
visualization workflows, enabling flexible reporting without duplicating queries.
Question 3
What is used as a compute resource for Databricks SQL?
- A. Single-node clusters
- B. Downstream BI tools integrated with Databricks SQL
- C. SQL warehouses
- D. Standard clusters
Answer:
C
Explanation:
Databricks SQL uses SQL warehouses as its compute resource. A SQL warehouse is a dedicated
compute engine designed specifically for executing SQL queries and powering dashboards within the
Databricks workspace. According to Databricks official documentation, SQL warehouses are
optimized for fast, scalable query execution, whereas clusters are used primarily for data engineering
and machine learning workloads.
Question 4
A data analyst wants the following output:
customer_name
number_of_orders
John Doe
388
Zhang San
234
Which statement will produce this output?
- A. SELECT customer_name, count(order_id) AS number_of_orders FROM customers JOIN orders ON customers.customer_id = orders.customer_id GROUP BY customer_name;
- B. SELECT customer_name, count(order_id) number_of_orders FROM customers JOIN orders ON customers.customer_id = orders.customer_id USE customer_name;
- C. SELECT customerjiame, (order_id) number_of_orders FROM customers JOIN orders ON customers.customer_id = orders.customer_id;
- D. SELECT customerjiame, count(order_id) FROM customers JOIN orders ON customers.customer_id = orders.customer_id GROUP BY customerjiame;
Answer:
A
Explanation:
To get the number of orders per customer, you need to join the customers and orders tables on the
customer_id, count the order_id, and group the results by customer_name. The correct SQL syntax,
as outlined in Databricks SQL documentation, is to use GROUP BY on the selected customer field and
use COUNT for aggregation. Only option A does this correctly, while the other options contain syntax
errors or incorrect field names.
Question 5
Which statement describes descriptive statistics?
- A. A branch of statistics that uses a variety of data analysis techniques to infer properties of an underlying distribution of probability.
- B. A branch of statistics that uses summary statistics to categorically describe and summarize data.
- C. A branch of statistics that uses summary statistics to quantitatively describe and summarize data.
- D. A branch of statistics that uses quantitative variables that must take on a finite or countably infinite set of values.
Answer:
C
Explanation:
Descriptive statistics refer to statistical methods used to describe and summarize the basic features
of data in a study. They provide simple summaries about the sample and the measures, often
including metrics such as mean, median, mode, range, and standard deviation. Databricks learning
materials highlight that descriptive statistics use summary statistics to quantitatively describe and
summarize data, providing insight into data distributions without making inferences or predictions.
Question 6
In which circumstance will there be a substantial difference between the variable’s mean and median
values?
- A. When the variable is of the categorical type
- B. When the variable is of the boolean type
- C. When the variable contains no outliers
- D. When the variable contains a lot of extreme outliers
Answer:
D
Explanation:
The mean is sensitive to extreme values, often called outliers, which can significantly skew the
average away from the true center of the data. The median, however, is a measure of central
tendency that is resistant to such outliers because it only considers the middle value(s) when the
data is ordered. Therefore, when a variable contains many extreme outliers, there will be a
substantial difference between the mean and the median. According to Databricks data analysis
materials, this is a fundamental concept when choosing summary statistics for reporting.
Question 7
A data analyst wants to create a Databricks SQL dashboard with multiple data visualizations and
multiple counters. What must be completed before adding the data visualizations and counters to
the dashboard?
A. All data visualizations and counters must be created using Queries.
B. A SQL warehouse (formerly known as SQL endpoint) must be turned on and selected.
C. A markdown-based tile must be added to the top of the dashboard displaying the dashboard's
name.
D. The dashboard owner must also be the owner of the queries, data visualizations, and counters.
Answer:
A
In Databricks SQL, when creating a dashboard that includes multiple data visualizations and counters,
it is imperative that each visualization and counter is based on a query. The process involves the
For each desired visualization or counter, write a SQL query that retrieves the necessary data.
After executing each query, utilize the results to create corresponding visualizations or counters.
Databricks SQL offers a variety of visualization types to represent data effectively.
Add the created visualizations and counters to your dashboard, arranging them as needed to convey
the desired insights.
By ensuring that all components of the dashboard are derived from queries, you maintain
consistency, accuracy, and the ability to refresh data as needed. This approach also facilitates easier
maintenance and updates to the dashboard elements.
Reference: Visualization in Databricks SQL
Question 8
Which location can be used to determine the owner of a managed table?
A. Review the Owner field in the table page using Catalog Explorer
B. Review the Owner field in the database page using Data Explorer
C. Review the Owner field in the schema page using Data Explorer
D. Review the Owner field in the table page using the SQL Editor
Answer:
A
In Databricks, to determine the owner of a managed table, you can utilize the Catalog Explorer
In your Databricks workspace, click on the Catalog icon in the sidebar to open Catalog Explorer.
Within Catalog Explorer, browse through the catalog and schema to locate the specific managed
table whose ownership you wish to verify.
Click on the table name to open its details page.
On the table's details page, review the Owner field, which displays the principal (user, service
principal, or group) that owns the table.
This method provides a straightforward way to ascertain the ownership of managed tables within the
Databricks environment. Understanding table ownership is essential for managing permissions and
ensuring proper access control.
Reference: Manage Unity Catalog object ownership
Question 9
A data scientist has asked a data analyst to create histograms for every continuous variable in a data
set. The data analyst needs to identify which columns are continuous in the data set.
What describes a continuous variable?
A. A quantitative variable that never stops changing
B. A quantitative variable Chat can take on a finite or countably infinite set of values
C. A quantitative variable that can take on an uncountable set of values
D. A categorical variable in which the number of categories continues to increase over time
Answer:
C
A continuous variable is a type of quantitative variable that can assume an infinite number of values
within a given range. This means that between any two possible values, there can be an infinite
number of other values. For example, variables such as height, weight, and temperature are
continuous because they can be measured to any level of precision, and there are no gaps between
possible values. This is in contrast to discrete variables, which can only take on specific, distinct
values (e.g., the number of children in a family). Understanding the nature of continuous variables is
crucial for data analysts, especially when selecting appropriate statistical methods and visualizations,
such as histograms, to accurately represent and analyze the data.
Question 10
A data analyst needs to share a Databricks SQL dashboard with stakeholders that are not permitted
to have accounts in the Databricks deployment. The stakeholders need to be notified every time the
dashboard is refreshed.
Which approach can the data analyst use to accomplish this task with minimal effort/
A. By granting the stakeholders' email addresses permissions to the dashboard
B. By adding the stakeholders' email addresses to the refresh schedule subscribers list
C. By granting the stakeholders' email addresses to the SQL Warehouse (formerly known as
endpoint) subscribers list
D. By downloading the dashboard as a PDF and emailing it to the stakeholders each time it is
refreshed
Answer:
B
To share a Databricks SQL dashboard with stakeholders who do not have accounts in the Databricks
deployment and ensure they are notified upon each refresh, the data analyst can add the
stakeholders' email addresses to the dashboard's refresh schedule subscribers list. This approach
allows the stakeholders to receive email notifications containing the latest dashboard updates
without requiring them to have direct access to the Databricks workspace. This method is efficient
and minimizes effort, as it automates the notification process and ensures stakeholders remain
informed of the most recent data insights.
Reference: Manage scheduled dashboard updates and subscriptions
Question 11
Where in the Databricks SQL workspace can a data analyst configure a refresh schedule for a query
when the query is not attached to a dashboard or alert?
A. Data bxplorer
B. The Visualization editor
C. The Query Editor
D. The Dashboard Editor
Answer:
C
In Databricks SQL, to configure a refresh schedule for a query that is not attached to a dashboard or
alert, a data analyst should use the Query Editor. Within the Query Editor, there is an option to set up
scheduled executions for queries. This feature enables the query to run at specified intervals,
ensuring that the results are updated regularly. By scheduling queries in this manner, analysts can
automate data refreshes and maintain up-to-date query results without manual intervention.
Reference: Schedule a query - Databricks Documentation
Question 12
What is a benefit of using Databricks SQL for business intelligence (Bl) analytics projects instead of
using third-party Bl tools?
A. Computations, data, and analytical tools on the same platform
B. Advanced dashboarding capabilities
C. Simultaneous multi-user support
D. Automated alerting systems
Answer:
A
Databricks SQL offers a unified platform where computations, data storage, and analytical tools
coexist seamlessly. This integration allows business intelligence (BI) analytics projects to be executed
more efficiently, as users can perform data processing and analysis without the need to transfer data
between disparate systems. By consolidating these components, Databricks SQL streamlines
workflows, reduces latency, and enhances data governance. While third-party BI tools may offer
advanced dashboarding capabilities, simultaneous multi-user support, and automated alerting
systems, they often require integration with separate data processing platforms, which can introduce
complexity and potential inefficiencies.
Reference:
Databricks AI & BI: Transform Data into Actionable Insights
Question 13
A data analyst is processing a complex aggregation on a table with zero null values and the query
returns the following result: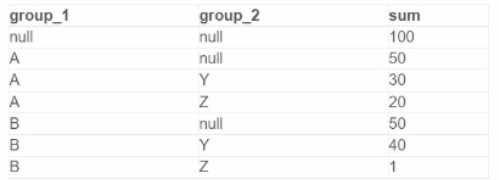
Which query did the analyst execute in order to get this result?
A)
B)
C)
D)
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer:
B
Question 14
What describes the variance of a set of values?
A. Variance is a measure of how far a single observed value is from a set ot va IN
B. Variance is a measure of how far an observed value is from the variable's maximum or minimum
value.
C. Variance is a measure of central tendency of a set of values.
D. Variance is a measure of how far a set of values is spread out from the sets central value.
Answer:
D
Variance is a statistical measure that quantifies the dispersion or spread of a set of values around
their mean (central value). It is calculated by taking the average of the squared differences between
each value and the mean of the dataset. A higher variance indicates that the data points are more
spread out from the mean, while a lower variance suggests that they are closer to the mean. This
measure is fundamental in statistics to understand the degree of variability within a
dataset.
WikipediaWikipedia+1Investopedia+1
Reference:
Variance - Wikipedia
Question 15
Data professionals with varying responsibilities use the Databricks Lakehouse Platform Which role in
the Databricks Lakehouse Platform use Databricks SQL as their primary service?
A. Data scientist
B. Data engineer
C. Platform architect
D. Business analyst
Answer:
D
In the Databricks Lakehouse Platform, business analysts primarily utilize Databricks SQL as their main
service. Databricks SQL provides an environment tailored for executing SQL queries, creating
visualizations, and developing dashboards, which aligns with the typical responsibilities of business
analysts who focus on interpreting data to inform business decisions. While data scientists and data
engineers also interact with the Databricks platform, their primary tools and services differ; data
scientists often engage with machine learning frameworks and notebooks, whereas data engineers
focus on data pipelines and ETL processes. Platform architects are involved in designing and
overseeing the infrastructure and architecture of the platform. Therefore, among the roles listed,
business analysts are the primary users of Databricks SQL.
Reference: The scope of the lakehouse platform