amazon AWS Certified Machine Learning Specialty - MLS-C01 exam practice questions
Questions for the AWS CERTIFIED MACHINE LEARNING SPECIALTY MLS C01 were updated on : Jul 11 ,2025
Page 1 out of 13. Viewing questions 1-15 out of 186
Question 1
A machine learning (ML) specialist is using Amazon SageMaker hyperparameter optimization (HPO) to improve a models
accuracy. The learning rate parameter is specified in the following HPO configuration:
During the results analysis, the ML specialist determines that most of the training jobs had a learning rate between 0.01 and
0.1. The best result had a learning rate of less than 0.01. Training jobs need to run regularly over a changing dataset. The
ML specialist needs to find a tuning mechanism that uses different learning rates more evenly from the provided range
between MinValue and MaxValue.
Which solution provides the MOST accurate result?
- A. Modify the HPO configuration as follows: Select the most accurate hyperparameter configuration form this HPO job.
- B. Run three different HPO jobs that use different learning rates form the following intervals for MinValue and MaxValue while using the same number of training jobs for each HPO job: Select the most accurate hyperparameter configuration form these three HPO jobs.
- C. Modify the HPO configuration as follows: Select the most accurate hyperparameter configuration form this training job.
- D. Run three different HPO jobs that use different learning rates form the following intervals for MinValue and MaxValue. Divide the number of training jobs for each HPO job by three: Select the most accurate hyperparameter configuration form these three HPO jobs.
Answer:
C
Question 2
A Marketing Manager at a pet insurance company plans to launch a targeted marketing campaign on social media to acquire
new customers. Currently, the company has the following data in Amazon Aurora:
Profiles for all past and existing customers
Profiles for all past and existing insured pets
Policy-level information
Premiums received Claims paid

What steps should be taken to implement a machine learning model to identify potential new customers on social media?
- A. Use regression on customer profile data to understand key characteristics of consumer segments. Find similar profiles on social media
- B. Use clustering on customer profile data to understand key characteristics of consumer segments. Find similar profiles on social media
- C. Use a recommendation engine on customer profile data to understand key characteristics of consumer segments. Find similar profiles on social media.
- D. Use a decision tree classifier engine on customer profile data to understand key characteristics of consumer segments. Find similar profiles on social media.
Answer:
C
Question 3
A retail company intends to use machine learning to categorize new products. A labeled dataset of current products was
provided to the Data Science team. The dataset includes 1,200 products. The labeled dataset has 15 features for each
product such as title dimensions, weight, and price. Each product is labeled as belonging to one of six categories such as
books, games, electronics, and movies.
Which model should be used for categorizing new products using the provided dataset for training?
- A. AnXGBoost model where the objective parameter is set to multi:softmax
- B. A deep convolutional neural network (CNN) with a softmax activation function for the last layer
- C. A regression forest where the number of trees is set equal to the number of product categories
- D. A DeepAR forecasting model based on a recurrent neural network (RNN)
Answer:
B
Question 4
A Data Scientist is developing a machine learning model to classify whether a financial transaction is fraudulent. The labeled
data available for training consists of 100,000 non-fraudulent observations and 1,000 fraudulent observations.
The Data Scientist applies the XGBoost algorithm to the data, resulting in the following confusion matrix when the trained
model is applied to a previously unseen validation dataset. The accuracy of the model is 99.1%, but the Data Scientist needs
to reduce the number of false negatives.
Which combination of steps should the Data Scientist take to reduce the number of false negative predictions by the model?
(Choose two.)
- A. Change the XGBoost eval_metric parameter to optimize based on Root Mean Square Error (RMSE).
- B. Increase the XGBoost scale_pos_weight parameter to adjust the balance of positive and negative weights.
- C. Increase the XGBoost max_depth parameter because the model is currently underfitting the data.
- D. Change the XGBoost eval_metric parameter to optimize based on Area Under the ROC Curve (AUC).
- E. Decrease the XGBoost max_depth parameter because the model is currently overfitting the data.
Answer:
D E
Question 5
A data engineer at a bank is evaluating a new tabular dataset that includes customer data. The data engineer will use the
customer data to create a new model to predict customer behavior. After creating a correlation matrix for the variables, the
data engineer notices that many of the 100 features are highly correlated with each other.
Which steps should the data engineer take to address this issue? (Choose two.)
- A. Use a linear-based algorithm to train the model.
- B. Apply principal component analysis (PCA).
- C. Remove a portion of highly correlated features from the dataset.
- D. Apply min-max feature scaling to the dataset.
- E. Apply one-hot encoding category-based variables.
Answer:
B D
Explanation:
Reference: https://royalsocietypublishing.org/doi/10.1098/rsta.2015.0202 https://scikit-
learn.org/stable/auto_examples/preprocessing/plot_all_scaling.html
Question 6
A machine learning (ML) specialist is administering a production Amazon SageMaker endpoint with model monitoring
configured. Amazon SageMaker Model Monitor detects violations on the SageMaker endpoint, so the ML specialist retrains
the model with the latest dataset. This dataset is statistically representative of the current production traffic. The ML
specialist notices that even after deploying the new SageMaker model and running the first monitoring job, the SageMaker
endpoint still has violations.
What should the ML specialist do to resolve the violations?
- A. Manually trigger the monitoring job to re-evaluate the SageMaker endpoint traffic sample.
- B. Run the Model Monitor baseline job again on the new training set. Configure Model Monitor to use the new baseline.
- C. Delete the endpoint and recreate it with the original configuration.
- D. Retrain the model again by using a combination of the original training set and the new training set.
Answer:
B
Question 7
An online reseller has a large, multi-column dataset with one column missing 30% of its data. A Machine Learning Specialist
believes that certain columns in the dataset could be used to reconstruct the missing data.
Which reconstruction approach should the Specialist use to preserve the integrity of the dataset?
- A. Listwise deletion
- B. Last observation carried forward
- C. Multiple imputation
- D. Mean substitution
Answer:
C
Explanation:
Reference: https://worldwidescience.org/topicpages/i/imputing+missing+values.html
Question 8
A company wants to create a data repository in the AWS Cloud for machine learning (ML) projects. The company wants to
use AWS to perform complete ML lifecycles and wants to use Amazon S3 for the data storage. All of the companys data
currently resides on premises and is 40 in size.
The company wants a solution that can transfer and automatically update data between the on-premises object storage and
Amazon S3. The solution must support encryption, scheduling, monitoring, and data integrity validation.
Which solution meets these requirements?
- A. Use the S3 sync command to compare the source S3 bucket and the destination S3 bucket. Determine which source files do not exist in the destination S3 bucket and which source files were modified.
- B. Use AWS Transfer for FTPS to transfer the files from the on-premises storage to Amazon S3.
- C. Use AWS DataSync to make an initial copy of the entire dataset. Schedule subsequent incremental transfers of changing data until the final cutover from on premises to AWS.
- D. Use S3 Batch Operations to pull data periodically from the on-premises storage. Enable S3 Versioning on the S3 bucket to protect against accidental overwrites.
Answer:
C
Explanation:
Configure DataSync to make an initial copy of your entire dataset, and schedule subsequent incremental transfers of
changing data until the final cut-over from on-premises to AWS. Reference: https://aws.amazon.com/datasync/faqs/
Question 9
A manufacturing company asks its machine learning specialist to develop a model that classifies defective parts into one of
eight defect types. The company has provided roughly 100,000 images per defect type for training. During the initial training
of the image classification model, the specialist notices that the validation accuracy is 80%, while the training accuracy is
90%. It is known that human-level performance for this type of image classification is around 90%.
What should the specialist consider to fix this issue?
- A. A longer training time
- B. Making the network larger
- C. Using a different optimizer
- D. Using some form of regularization
Answer:
D
Explanation:
Reference: https://acloud.guru/forums/aws-certified-machine-learning-specialty/discussion/-
MGdBUKmQ02zC3uOq4VL/AWS%20Exam%20Machine%20Learning
Question 10
The displayed graph is from a forecasting model for testing a time series.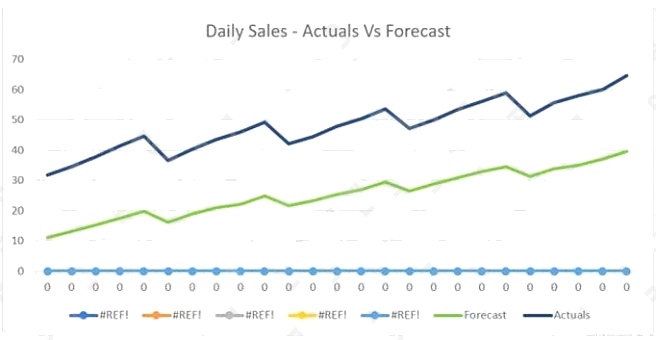
Considering the graph only, which conclusion should a Machine Learning Specialist make about the behavior of the model?
- A. The model predicts both the trend and the seasonality well
- B. The model predicts the trend well, but not the seasonality.
- C. The model predicts the seasonality well, but not the trend.
- D. The model does not predict the trend or the seasonality well.
Answer:
A
Question 11
A company needs to quickly make sense of a large amount of data and gain insight from it. The data is in different formats,
the schemas change frequently, and new data sources are added regularly. The company wants to use AWS services to
explore multiple data sources, suggest schemas, and enrich and transform the data. The solution should require the least
possible coding effort for the data flows and the least possible infrastructure management.
Which combination of AWS services will meet these requirements?
- A. Amazon EMR for data discovery, enrichment, and transformation reporting and getting insights
- B. Amazon Kinesis Data Analytics for data ingestion
- C. AWS Glue for data discovery, enrichment, and transformation reporting and getting insights
- D. AWS Data Pipeline for data transfer
Answer:
A
Question 12
A Machine Learning Specialist is given a structured dataset on the shopping habits of a companys customer base. The
dataset contains thousands of columns of data and hundreds of numerical columns for each customer. The Specialist wants
to identify whether there are natural groupings for these columns across all customers and visualize the results as quickly as
possible.
What approach should the Specialist take to accomplish these tasks?
- A. Embed the numerical features using the t-distributed stochastic neighbor embedding (t-SNE) algorithm and create a scatter plot.
- B. Run k-means using the Euclidean distance measure for different values of k and create an elbow plot.
- C. Embed the numerical features using the t-distributed stochastic neighbor embedding (t-SNE) algorithm and create a line graph.
- D. Run k-means using the Euclidean distance measure for different values of k and create box plots for each numerical column within each cluster.
Answer:
B
Question 13
A Mobile Network Operator is building an analytics platform to analyze and optimize a company's operations using Amazon
Athena and Amazon S3.
The source systems send data in .CSV format in real time. The Data Engineering team wants to transform the data to the
Apache Parquet format before storing it on Amazon S3.
Which solution takes the LEAST effort to implement?
- A. Ingest .CSV data using Apache Kafka Streams on Amazon EC2 instances and use Kafka Connect S3 to serialize data as Parquet
- B. Ingest .CSV data from Amazon Kinesis Data Streams and use Amazon Glue to convert data into Parquet.
- C. Ingest .CSV data using Apache Spark Structured Streaming in an Amazon EMR cluster and use Apache Spark to convert data into Parquet.
- D. Ingest .CSV data from Amazon Kinesis Data Streams and use Amazon Kinesis Data Firehose to convert data into Parquet.
Answer:
B
Question 14
This graph shows the training and validation loss against the epochs for a neural network.
The network being trained is as follows:
Two dense layers, one output neuron
100 neurons in each layer
100 epochs
Random initialization of weights
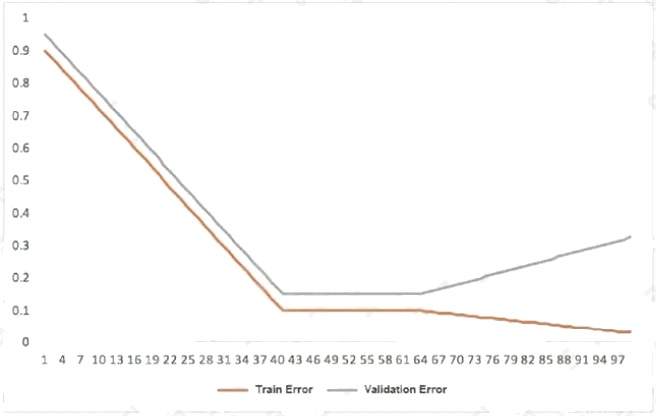
Which technique can be used to improve model performance in terms of accuracy in the validation set?
- A. Early stopping
- B. Random initialization of weights with appropriate seed
- C. Increasing the number of epochs
- D. Adding another layer with the 100 neurons
Answer:
C
Question 15
A financial services company wants to adopt Amazon SageMaker as its default data science environment. The company's
data scientists run machine learning (ML) models on confidential financial data. The company is worried about data egress
and wants an ML engineer to secure the environment. Which mechanisms can the ML engineer use to control data egress
from SageMaker? (Choose three.)
- A. Connect to SageMaker by using a VPC interface endpoint powered by AWS PrivateLink.
- B. Use SCPs to restrict access to SageMaker.
- C. Disable root access on the SageMaker notebook instances.
- D. Enable network isolation for training jobs and models.
- E. Restrict notebook presigned URLs to specific IPs used by the company.
- F. Protect data with encryption at rest and in transit. Use AWS Key Management Service (AWS KMS) to manage encryption keys.
Answer:
B D F